面试指南
本文于 909 天之前发表,文中内容可能已经过时。
[TOC]
框架篇
EventBus
简述EventBus的理解
EventBus作为通信事件传递的总线,你无需控制值的传递,也无需通过广播等低效实现,通过EventBus在你需要发送的地方post信息,在你需要接收的地方接收信息处理即可,(前提是register过)
EventBus的五种线程模式
- POSTING:默认,发布和订阅在同一个线程,同发布者一个线程(主—>主 , 子—>子),最小的开销,因为不用切换线程,避免了线程的完全切换,使用此模式的事件处理程序必须快速返回,以避免阻塞可能是主线程的发布线程。
- MAIN:事件处理函数的线程在主线程(UI)线程。不能进行
耗时操作,订阅者需快速返回以免阻塞主线程 - MAIN_ORDERED:事件处理函数的线程在主线程(UI)线程。不会阻塞线程
- BACKGROUND:处理函数在后台线程,不能进行UI操作。发布在主线程,订阅会开启一个新的后台线程。发布在后台线程,事件处理函数也在该后台线程
- ASYNC:无论事件发布的线程是哪一个,都会重新开辟一个新的子线程运行,不能进行UI操作
EventBus的事件类型
接收事件必须是public修饰符修饰,不能用static关键字修饰,不能是抽象的(abstract)
- 普通事件:先订阅在发布,发布到订阅者后进行处理
- 粘性事件:支持先发布在订阅,当订阅者订阅后会自动发送到订阅者进行处理,发送粘性事件EventBus.postSticky(),接收粘性事件sticky = true
为什么必须是public?
因为源码定义
优先级
优先级高的订阅者优先接收到任务
简述源码分析事件
- register:通过注解初始化订阅方法后,在register后,在缓存中获取所有该订阅者的方法,循环遍历订阅,新建newSubscription方法,根据priority优先级将newSubscription方法放入subscriptions中,判断如果
是粘性事件,则执行其对应的订阅方法。 - unregister:从typesBySubscriber获取订阅事件类型,根据订阅事件类型从subscriptionsByEventType获取订阅者信息,将subscription的active置为false,并移除该subscription
索引如何理解?
EventBus 3.0以后,采用Subscribe注解配置事件订阅方法,采用反射的方式来查找订阅事件的方法,我们都知道反射对性能是有影响的,所以提出了索引的概念。
在项目编译时,通过配置,生成一个辅助类用来存储订阅信息,原理是HashMap,存储注册类的class类型和事件订阅方法的信息,提高速度3-4倍
MAIN和MAIN_ORDERED的区别?
在
MAIN模式下,如果事件发布者post事件也是在主线程的话,会阻塞post事件所在的线程,意思是连续post多个事件,如果接收事件方法执行完,才能post下一个事件**post(1) ——> onReceiveMsg(1) ——>post(2)——>onReceiveMsg(2)——>post(3)——>onReceiveMsg(3)**如果事件发布者post事件不在主线程,连续post多个事件,同时在主线程是接收事件是耗时操作的话,执行的流程是非阻塞的
**post(1)——>post(2)——>psot(3)——>onReceiveMsg(3)** 或 **post(1)——>post(2)——>psot(3)——>onReceiveMsg(2)——>onReceiveMsg(3)**MAIN_ORDERED模式下,无论什么场景都是非阻塞的
EventBus可否跨进程问题?
不能,单进程间通信
HermesEventBus——>饿了吗开发框架,可应用于单进程和多进程。
使用IPC机制,首先选择一个主进程,其他则为子进程,每一个event会经过4步:
- 使用Hermes库将event传递给主进程。
- 主进程使用EventBus在主进程内部发送event。
- 主进程使用Hermes库将event传递给所有的子进程。
- 每个子进程使用EventBus在子进程内部发送event。
BackgroundThread和Async区别
BackgroundThread:发布在主线程,新开辟子线程中执行。发布在子线程,则在子线程中执行,这个子线程是阻塞式的,按顺序交付所有事件,所以也不适合做耗时任务,因为多个事件共用这一个后台线程
Async:无论发布在哪一个线程,都会在重新开辟一个子线程执行
EventBus的优缺点:
优点:
EventBus是greenrobot公司出的另一款开源框架,这个框架是针对Android优化的发布/订阅事件总线,使用EventBus可以极大的减少我们程序的耦合度。
调度灵活。不依赖于 Context,使用时无需像广播一样关注 Context 的注入与传递。
使用简单。
快速且轻量。
完全解耦了请求链之间的关系,避免了请求者被长持有,
比广播更轻量
可以定义在调用线程、主线程、后台线程、异步。
粘性事件
优先级概念
为了避免频繁的向主线程 sendMessage()(Handler机制),EventBus 的做法是在一个消息里尽可能多的处理更多的消息事件,所以使用了 while 循环,持续从消息队列 queue 中获取消息。
同时为了避免长期占有主线程,间隔 10ms (maxMillisInsideHandleMessage = 10ms)会重新发送 sendMessage(),用于让出主线程的执行权,避免造成 UI 卡顿和 ANR。
缺点:
各种Event的定义工作量大。每次传的内容不一样,就需要重新定义一个JavaBean
单向传播
需要显性注册
EventBus如何做到线程切换
1 | private void postToSubscription(Subscription subscription, Object event, boolean isMainThread) { |
主要分为主线程执行和子线程执行,当为主线程时:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61public class HandlerPoster extends Handler implements Poster {
private final PendingPostQueue queue;
private final int maxMillisInsideHandleMessage;
private final EventBus eventBus;
private boolean handlerActive;
protected HandlerPoster(EventBus eventBus, Looper looper, int maxMillisInsideHandleMessage) {
super(looper);
this.eventBus = eventBus;
this.maxMillisInsideHandleMessage = maxMillisInsideHandleMessage;
queue = new PendingPostQueue();
}
public void enqueue(Subscription subscription, Object event) {
PendingPost pendingPost = PendingPost.obtainPendingPost(subscription, event);
synchronized (this) {
queue.enqueue(pendingPost);
if (!handlerActive) {
handlerActive = true;
if (!sendMessage(obtainMessage())) {
throw new EventBusException("Could not send handler message");
}
}
}
}
public void handleMessage(Message msg) {
boolean rescheduled = false;
try {
long started = SystemClock.uptimeMillis();
//循环处理消息事件,避免重复sendMessage()
while (true) {
PendingPost pendingPost = queue.poll();
if (pendingPost == null) {
synchronized (this) {
// Check again, this time in synchronized
pendingPost = queue.poll();
if (pendingPost == null) {
handlerActive = false;
return;
}
}
}
eventBus.invokeSubscriber(pendingPost);
long timeInMethod = SystemClock.uptimeMillis() - started;
//避免长期占用主线程,间隔10ms重新sendMassage()
if (timeInMethod >= maxMillisInsideHandleMessage) {
if (!sendMessage(obtainMessage())) {
throw new EventBusException("Could not send handler message");
}
rescheduled = true;
return;
}
}
} finally {
handlerActive = rescheduled;
}
}
}
使用HandlerPoster将任务通过sendMessage方法发送到主线程执行,通过消息队列存储该handler的任务,通过10ms发送一次任务,防止主线程卡顿,MAIN情况下,如果在主线程,直接执行。MAIN_ORDER的情况下,全部交给handler异步执行,所以区别于MAIN不是同步的
1 | final class BackgroundPoster implements Runnable, Poster { |
子线程执行是通过线程池进行管理,内部也存在一个消息队列,按顺序执行任务,对于BACKGROUND情况下,同时只会使用线程池中的一个线程,而Async直接放入线程池,让线程池去规划线程。当线程池中等待任务过多时,会触发oom(线程池是newCachedThreadPool(),则线程为非核心线程MAX)
粘性事件的原理
普通事件是先注册后发布,而粘性事件可以先发布后注册,实现方式上是这样的:
发送时会将粘性事件的事件类型和对应事件保存起来,在执行post方法,在注册后,如果是粘性事件,会多走一步类似于post的方法,触发进行分发
如何判断当前线程是否为主线程?
在发布事件的地方判断发送线程和主线程的Looper对象是否相等1
return Looper.getMainLooper() == Looper.myLooper();
如何优化EventBus
- 尽量使用索引功能,避免不必要的反射,提升性能
- 增加EventBus的进程间通信
为什么使用ConcurrentHashMap保存数据
因为EventBus是单进程、多线程间通信,可能涉及到线程安全问题,使用ConcurrentHashMap可以有效解决线程安全和效率。
Okhttp3
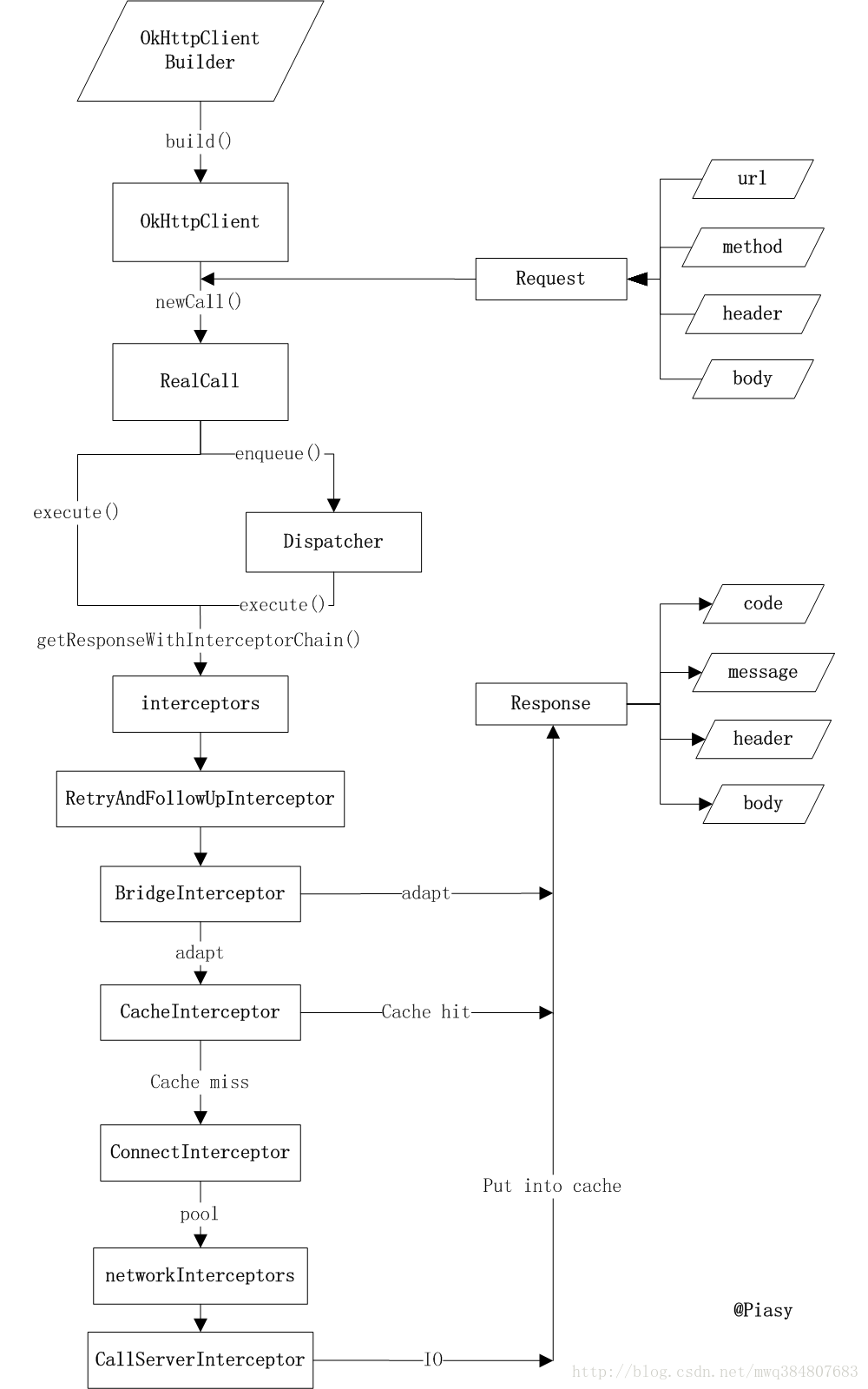
简述OkHttp
是基于Socket的封装,主要有三个类:Response、Request、Call
同步使用client.excute(); 异步使用client.enqueue();
OkHttp的高效在于内部有一个Dispatcher,是okhttp维护的一个线程池,对最大连接数(并发),host最大访问量做了定义,维护了3个队列(同步正在执行,准备执行,异步正在执行)和一个线程池(0~max)
内部还维护了连接池,实现了复用机制,减少重复握手
提供缓存机制。
有几个拦截器,分别是干什么的?
client.intercepters():应用拦截器
RetryAndFollowUpIntercepter:重试和重定向机制,最大重试次数为20,构造StreamAllocation,创建缓存池,复用
BridgeIntercepter:将用户构造的请求转化为服务器识别的请求,将服务器返回的响应转化为用户识别的响应,添加keep-alive,供连接池复用
CacheIntercepter:缓存读取和更新
ConnectIntercepter:dns解析与服务器建立连接(握手结束),它利用 Okio 对 Socket 的读写操作进行封装,它对 java.io 和 java.nio 进行了封装,让我们更便捷高效的进行 IO 操作
client.networkIntercepter:网络拦截器
CallServerIntercepter:最后一个拦截器,负责向服务器发送请求和接收服务器的响应
采用责任链模式,将请求和发送分别处理,并且可以动态添加中间的处理方实现对请求的处理、短路等操作。
addNetworkInterceptor() (网络拦截器)和addInterceptor() (应用拦截器)
区别就是一个靠前一个靠后,其中经过的拦截器会导致不一样的结果
RetryAndFollowUpIntercepter中怎么进行重定向?
最大重试次数为20次1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51case HTTP_PERM_REDIRECT://307
case HTTP_TEMP_REDIRECT://308
// "If the 307 or 308 status code is received in response to a request other than GET
// or HEAD, the user agent MUST NOT automatically redirect the request"
if (!method.equals("GET") && !method.equals("HEAD")) {
return null;
}
// fall-through
case HTTP_MULT_CHOICE://300
case HTTP_MOVED_PERM://301
case HTTP_MOVED_TEMP://302
case HTTP_SEE_OTHER://303
// Does the client allow redirects?
if (!client.followRedirects()) return null;
String location = userResponse.header("Location");
if (location == null) return null;
HttpUrl url = userResponse.request().url().resolve(location);
// Don't follow redirects to unsupported protocols.
if (url == null) return null;
// If configured, don't follow redirects between SSL and non-SSL.
boolean sameScheme = url.scheme().equals(userResponse.request().url().scheme());
if (!sameScheme && !client.followSslRedirects()) return null;
// Most redirects don't include a request body.
Request.Builder requestBuilder = userResponse.request().newBuilder();
if (HttpMethod.permitsRequestBody(method)) {
final boolean maintainBody = HttpMethod.redirectsWithBody(method);
if (HttpMethod.redirectsToGet(method)) {
requestBuilder.method("GET", null);
} else {
RequestBody requestBody = maintainBody ? userResponse.request().body() : null;
requestBuilder.method(method, requestBody);
}
if (!maintainBody) {
requestBuilder.removeHeader("Transfer-Encoding");
requestBuilder.removeHeader("Content-Length");
requestBuilder.removeHeader("Content-Type");
}
}
// When redirecting across hosts, drop all authentication headers. This
// is potentially annoying to the application layer since they have no
// way to retain them.
if (!sameConnection(userResponse, url)) {
requestBuilder.removeHeader("Authorization");
}
return requestBuilder.url(url).build();
如果返回响应code是307和308,则只对get和head类型的请求进行重定向。
如果返回请求为PROPFIND,则重新发送的请求都为保持原状,如果不是propFind,则重新请求的都会被设置为get请求,且请求信息为空
RetryAndFollowUpInterceptor的intercept中先是创建了StreamAllocation对象,然后开启while(true)无限循环。接着在这个循环中先调用下层拦截器去网络请求,若请求期间发生异常,判断能否重试,能就continue进行下一轮循环,否则抛异常退出循环结束方法。如果下层拦截器请求完成返回response,通过response的状态码判断是否需要重定向,若需要重定向,修改request后进行下一轮循环,否则返回response结束方法。
什么是连接池?
OkHttp的底层是通过Java的Socket发送HTTP请求与接受响应的(这也好理解,HTTP就是基于TCP协议的),但是OkHttp实现了连接池的概念,
即对于同一主机的多个请求,其实可以公用一个Socket连接,而不是每次发送完HTTP请求就关闭底层的Socket,这样就实现了连接池的概念。
简述连接池的复用?
okhttp中所有的请求都被抽象为RealConnection,而ConnectionPool就是管理这些connection的,共享一个Address的链接可以复用
ConnectionPool,默认大小是5,每个链接存储5分钟,使用keep-alive,达到久连接,所以默认keep-alive是5分钟,也可以自定义
excutor:线程池,监测时间并释放连接的后台线程
connections:缓存池。是一个双端列表,这里用作栈
routeDatabase:记录连接失败router(路由)
使用put方法将连接放入缓存池,并清除闲置的线程,对缓存池进行排序(对比最大闲置时间),使用StreamAllocation复用请求
StreamAllocation的初始化在RetryAndFllowUpIntercepter。
在StreamAllocation调用newStream进行初始化,其中使用get方法在缓存池中查找相同的请求,如果找到就复用这条请求,没找到就新建连接并put到缓存池
连接池的工作就这么多,并不负责,主要就是管理双端队列Deque
,可以用的连接就直接用,然后定期清理连接,同时通过对StreamAllocation的引用计数实现自动回收。
简述StreamAllocation
StreamAllocation是用来协调connections,stream和Call(请求)的。
HTTP通信执行网络请求Call需要在连接Connection上建立一个新的流Stream,我们将StreamAllocation称之流 的桥梁,它负责为一次请求寻找连接并建立流,从而完成远程通信。
其初始化在RetryAndFllowUpIntercepter,再次使用在CallServerInterceptor,复用机制使用该方法调用,减少一个三次握手的时间(不需要握手)
OKIO的优势
- 更加轻便,速度更快,使用更快
- 实现缓存结构,对cpu和内存进行优化,避免频繁gc(Segment链表实现)
- 功能强大,支持阻塞和非阻塞IO
- 支持多种类型,想比较于java.io和java.nio,不需要庞大的装饰类
Dispatcher的理解
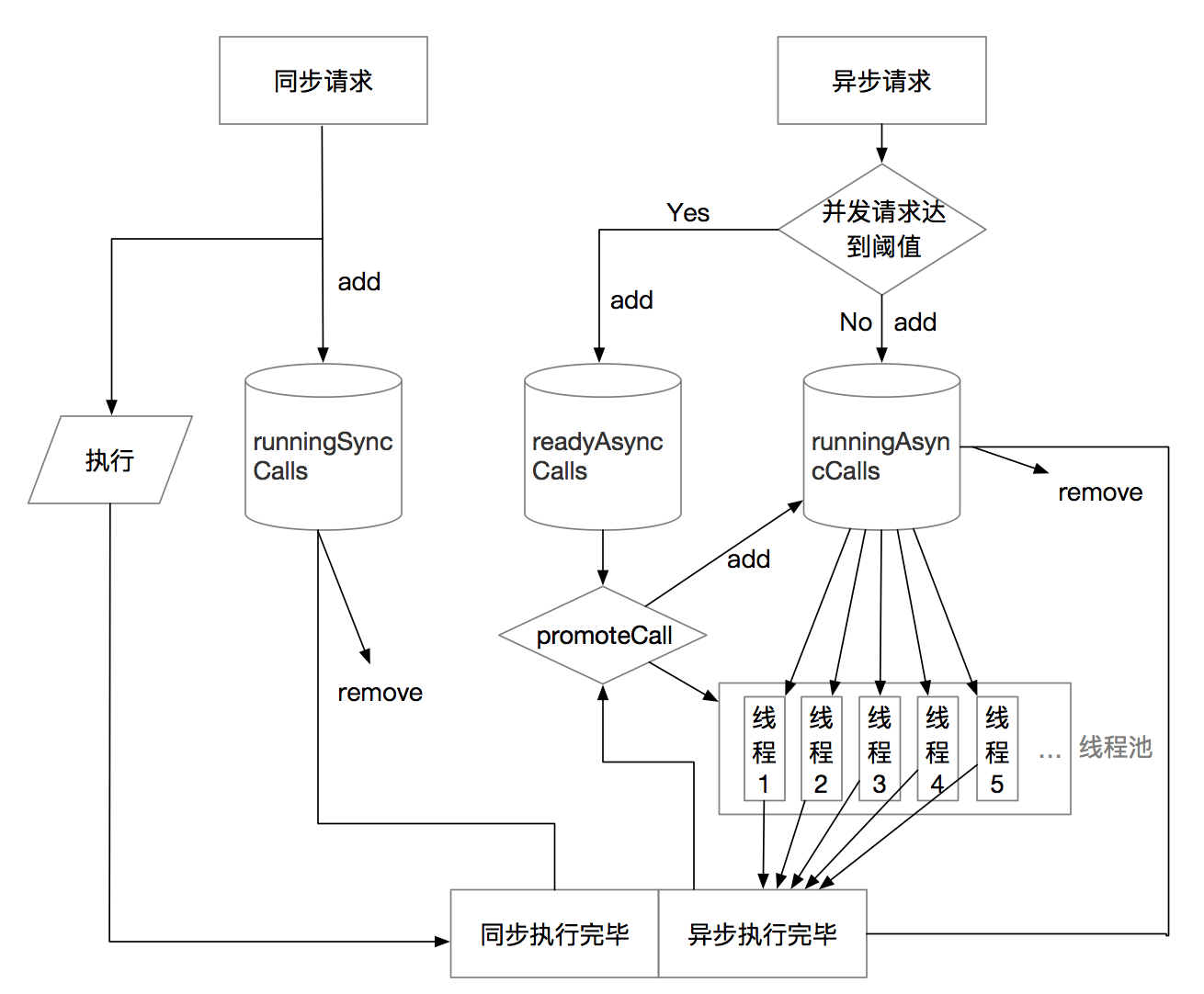
内部维护了三个队列,分别为:
- runningAsyncCalls:正在请求的异步队列
- readyAsyncCalls:准备请求的异步队列\等待请求的异步队列
- runningSyncCalls:正在请求的同步队列
maxRequest:默认64。这是okhttp允许的最大请求数量。
maxRequestsPerHost :默认5。这是okhttp对同一主机允许的最大请求数量。
同步执行源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 public Response execute() throws IOException {
synchronized (this) {
//此处除去一些其他代码
//...
try {
//通知Dispatcher这个Call正在被执行,同时将此Call交给Dispatcher
//Dispatcher可以对此Call进行管理
client.dispatcher().executed(this);
//请求的过程,注意这行代码是阻塞的,直到返回result!
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} finally {
//此时这个请求已经执行完毕了,通知Dispatcher,不要再维护这个Call了
client.dispatcher().finished(this);
}
}
try 中的return执行完成后,执行finally语句,所以不论请求成功或者失败,都会关闭这个请求
异步执行源码:1
2
3
4
5
6
7
8
9
10
11 public void enqueue(Callback responseCallback) {
synchronized (this) {
//判断是否已经执行过了
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
//捕获调用栈的信息,用来分析连接泄露
captureCallStackTrace();
//封装一个AsyncCall交给Dispatcher调度
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
1 | synchronized void enqueue(AsyncCall call) { |
简述OKhttp的缓存机制
okhttp有具备网络缓存机制,短时间内重复请求会复用缓存的数据,这样节省流量,应用也会很流畅。但是okhttp本身默认是不打开缓存机制的,需要配置后才能启动。
okhttp的缓存机制是以DiskLruCache(最近最少使用算法(Least recently used))为基础的,仅支持文件存储。
MD5(url)作为key,value是存储的服务端响应数据
默认不开启缓存机制
文件存储
DiskLruCache写入是依赖于okio的,内部实现类似于LinkedHashMap,键值对获取。
使用DiskLruCache,仅支持get请求的缓存
- 如果服务器支持缓存,即response携带Cache-control属性,则当你打开okhttp缓存即开始缓存,通过属性控制类型
- 如果服务器不支持缓存或者okhttp不想按照服务器缓存策略来存储,通过自定义拦截器重写response的头部即可
- 客户端不支持缓存,则可以不缓存,不理会服务器的cache-control属性
可以直接使用CacheControl类,包含
- CacheControl.FORCE_NETWORK,即强制使用网络请求
- CacheControl.FORCE_CACHE,即强制使用本地缓存,如果无可用缓存则返回一个code为504的响应
1 | max-stale指示客户机可以接收超出超时期间的响应消息。如果指定max-stale消息的值,那么客户机可以接收超出超时期指定值之内的响应消息。 |
添加自定义网络拦截器,在其中改变Response的响应头,添加Cache-control,后续回到CacheIntercepter中时,就会执行缓存策略。
CacheControl.Builder
1 | - noCache();//不使用缓存,用网络请求 |
CacheStrategy:缓存策略类,通过响应头信息与服务器端信息进行对比,最后返回是否使用新的网络请求还是直接使用缓存。其中存储的是Request请求体和Response响应体的具体内容
1 | /** 如果不使用网络,则 networkRequest为 null */ |
根据输出的networkRequest和cacheResponse的值是否为null给出不同的策略,如下:
| networkRequest | cacheResponse | result 结果 |
|---|---|---|
| null(不使用网络) | null(不使用缓存) | only-if-cached (表明不进行网络请求,且缓存不存在或者过期,一定会返回503错误) |
| null | non-null | 不进行网络请求,直接返回缓存,不请求网络 |
| non-null | null | 需要进行网络请求,而且缓存不存在或者过去,直接访问网络 |
| non-null | non-null | Header中包含ETag/Last-Modified标签,需要在满足条件下请求,还是需要访问网络(根据情况使用) |
如果网络不为null,则使用网络请求,如果网络为null,当缓存不为null,则使用缓存,当缓存为null时,返回503错误
为什么只做get的缓存?
其他响应成本大,效率低
线程池
okhttp其中有一个dispatcher对最大连接数(并发),host最大访问量做了定义,维护了3个队列(同步正在执行,准备执行,异步正在执行)和一个线程池(0~max)
该线程池类似于CachedThreadPool,没有核心线程,全是非核心线程,超时时间是60s,即60s后回收该线程,其队列为空,没有容量,是一种特殊的队列,适用于执行短时的大量任务。
okhttp的优势?
最大特点是,intercepter拦截器,连接池复用,okio io处理,线程池处理(全是非核心线程),支持http1.0,1.1,2.0
okio内部封装链表数据存储,比较之前的数组存储,更加节省空间,还可以复用
长连接(websocket)和久连接(keep-alive)的区别
调用的是equeue异步方法,将长连接放入线程池中不会被释放掉
- 1.1推出keep-alive机制,服务器不会主动发送请求,一个request返回一个response。
- 减少了握手的次数而已
- 久连接是同步串行处理的,当某一个请求因为网络,服务器等原因阻塞时,那么后面的请求都得不到处理
- http头部太大,传输耗时
- 实时性得不到保证
http是单向的,websocket属于应用层协议,使用http1.1的101码进行握手状态判断
websocket建立连接是使用https连接,三次握手,在通信过程中
- 以ws开头
- 握手成功后,复用连接发送请求和接收
- 不需要发送header信息
- 服务端客户端平等,可以相互建立连接,http久连接是基于http的,符合http协议。
最开始使用get请求进行握手,携带Upgrade: websocket ,告知服务器上升为websocket协议,成功后,使用web socket数据流(帧)进行通信,设置超时时间为永不超时,客户端设置循环,一直从服务端取消息。
使用http的get请求进行3次握手协议,使用http1.1版本的101状态码返回成功后,就不需要http交互了,后续采用web socket流进行通信,减少包体
使用标准的HTTP协议无法实现WebSocket,只有支持那些协议的专门浏览器才能正常工作。
websocket的握手和http的握手有什么区别?
使用http的get请求进行握手,基本一致,额外传输了header的信息标记为websocket。
MQTT理解
发布订阅者模式,低带宽,低开销的即时通信协议,基于tcp/ip协议,成为IOT通讯标准
消息体如下:固定头部+可变头部+消息体,整个消息体比较轻便,便于交互及时
| 固定报头(fixed header) | 可变报头(variable header) | 荷载(payload) |
|---|---|---|
| 所有报文都包含,数据包类型及数据包的分组类标识 | 部分报文包含,数据包类型决定了可变头是否存在及其具体内容 | 部分报文包含,表示客户端收到的具体内容 |
基于二进制实现,MQTT运行于http上,所以明文传输,如果位于https中,则可以使用TLS加密传输
发布者,订阅者模式:客户端是发布者和订阅者,服务端是代理服务器
MQTT和websocket的区别?
MQTT面向原生设备,基于二进制实现,提供一对多的通信方式,采用发布/订阅模式传输
websocket面向web设备,是全双工通信
Retrofit
简述
基于Okhttp的RESTFUL Api请求工具,Retrofit可以让你简单到调用一个Java方法的方式去请求一个api,这样App中的代码就会很简洁方便阅读
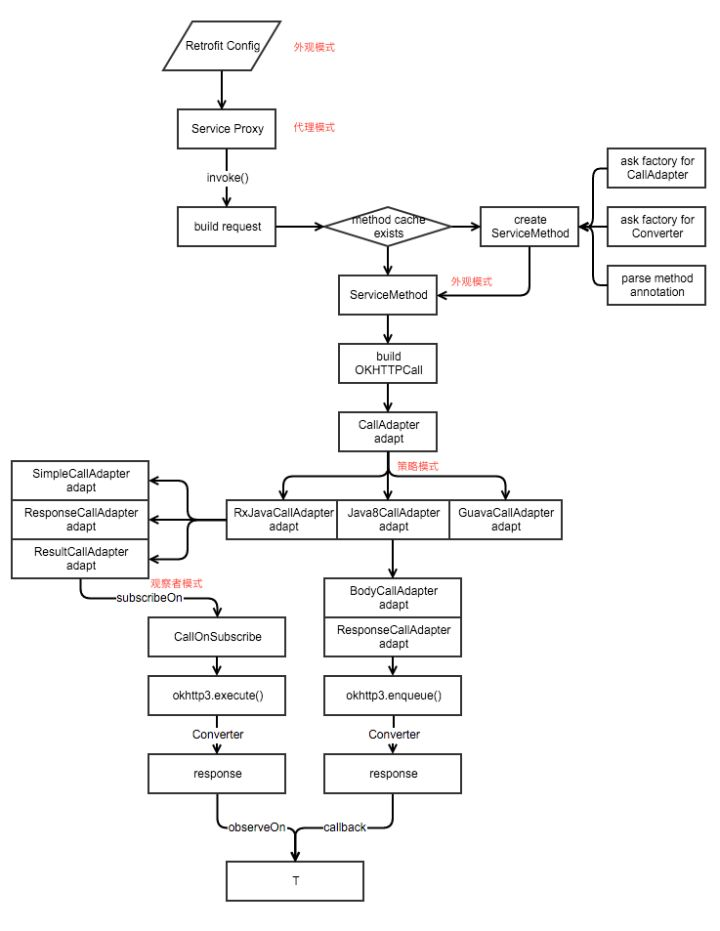
Retrofit通过java接口及注解来描述网络请求,并用动态代理的方式生成网络请求的Request,通过调用相应的网络框架(默认Okhttp)去发起网络请求,并将返回的Response通过converterFactory转化成相应的model,最后通过CallAdapter转换成其他的数据方式(Rxjava Observable)
Retrofit.create()方法是Retrofit的核心,其中,使用Proxy.newProxyInstance()方法创建ServiceMethod,具体实现是在InvocationHandler类中的invoke方法,实现了动态代理的形式,而这个InvocationHandler对象就是代理对象,这个对象是在运行时动态生成的。
Retrofit中的动态代理
1 | public <T> T create(final Class<T> service) { |
通过动态代理生成InvocationHandler类,在内部,创建一个ServiceMethod,存储接口的请求信息,构建一个OKhttpCall对象,初始化网络请求
Retrofit的优势
Retrofit是对okhttp的二次封装,解决okhttp中接口请求、数据结果返回和接口调用的短板。
- 规划了interface接口类,整合所有接口调用的详细内容,便于调用,降低耦合性。
- 配合RxJava,okhttp,职责明确。RxJava负责异步处理,Retrofit负责请求的数据和结果的展示,okhttp负责接口请求和返回的具体过程
- Retrofit主要负责应用层面的封装,就是说主要面向开发者,方便使用,比如请求参数,响应数据的处理,错误处理等等。
- OkHttp主要负责socket部分的优化,比如多路复用,buffer缓存,数据压缩等等。
- 相对于okhttp来说,使用动态代理生成Request对象,不用每次调用自己实现
- 网络结果线程切换库(RxJava,普通),网络结果格式化库(Gson,xml)等可以做到随意替换和支持
动态代理和静态代理的区别
静态代理:
由程序员创建或工具生成的代理类,在运行前就存在代理类的字节码文件,代理类和委托类的关系已经确定
动态代理:
在程序运行过程中,通过反射实现对代理类的动态创建,可以代理多个方法。(InvocationHandler、CGLib)
Butterknife———view的注入
简述Butterknife
初始化控件会写大量的findViewById(),setOnClickListener()方法,很繁琐,该框架使用注解的方式实现辅助代码的生成,简化这些代码。
该框架是基于java注解机制实现的,也就是在编译期间就初始化好了一个viewBinding类(view和点击事件的处理),生成findViewById来绑定布局,不用开发者每次去初始化
Butterknife为什么初始化控件不能用private和static
因为在编译期间构建view的绑定事件会报错,无法访问private变量,否则,要加入反射,导致性能问题
static可能会导致内存泄漏,而且外部可以访问。
ButterKnife为什么执行效率为什么比其他注入框架高?它的原理是什么
解析注解处理器, 对比Butterknife,Dagger2,DBFlow。
没有反射机制,使用自定义注解框架
继承问题
butterknife继承后,子类可以使用父类控件,但是必须在setContView之后进行绑定。如果在子view进行绑定控件,但是父类找不到子类的控件,因为生成的是子view_ViewBinding类,父类获取不到
缺点
- 每个Activity会生成一个类,增大包体积
- butterknife可以称之为view的注入,对findviewById包装更加简单,功能单一
ViewBinding最终最好的解决方案
简析ViewBinding
在build.gradle中开启ViewBinding1
2
3
4android {
//...
viewBinding.enabled = true
}
android studio会将xml文件中所有文件在编译过程中生成xxxBinding类,这个类有三种初始化方法1
binding = LayoutSecondBinding.inflate(getLayoutInflater());
在Activity或Fragment中调用inflate方法进行初始化1
2
3inflate(LayoutInflater inflater)
inflate(LayoutInflater inflater,ViewGroup parent,boolean attachToParent)
bind(View rootView)
最终三个方法都会走到bind方法中,在这个方法中,对View进行findViewById操作
ViewBinding和Butterknife的区别
ViewBinding会处理空安全,类型安全,还可以兼容java和kotlin。最新版本Gradle中设置对R文件的修改,R文件中的id不再是final的,(Fragment中R文件不是final的时候,Butterknife使用生成R2文件的做法围魏救赵)这样就会影响注解的使用,butterknife就被迫下台
Viewbinding根正苗红,官方支持就是最大优势
Viewbinding如何处理include布局?
xml布局中存在include布局的,需要给include布局添加id,生成一个includexxxBinding文件,在xxxBinding类中做映射体现。
内部view由final修饰,保证view不能被重新创建的view替换(引用不可修改),但是其内部的值可以修改
注解原理
简析
元注解:修饰注解的注解,
- @Target:注解的作用目标(修饰方法,类还是字段)
- @Retention:注解的生命周期
- SOURCE:仅存在java源文件中,经过编译器后就丢弃,适用于一些检查行的操作,比如@Override
- CLASS:编译class文件时生效,适用于在编译时做一些预处理操作,比如Butterknife的@BindView,在编译时,通过注解器生成一些辅助代码,完成完整的功能
- RUNTIME:保留在运行时VM中可以通过反射获取注解。适用于一些需要运行时动态获取注解信息,类似反射获取注解等,比如EventBus的@Subscribe
- @Documented:注解是否应当被包含在JavaDoc文档中
- @Inherited:是否允许子类继承该注解
- AnnotationInvocationHandler:专门处理注解的Handler
代码的生命周期包含:编码(SOURCE)—->编译(CLASS)—->运行(RUNTIME)
默认时注解在编译阶段,即CLASS阶段
本质:一个继承了Annotation接口的接口
- 运行时处理:使用反射获取当前的所需要的东西
- 编译时处理:APT技术,即编译期扫描java文件的注解,并传递到注解处理器,注解处理器可根据注解生成新的java文件
APT(Annotation Processing Tool)编译期解析注解
注解的种类
- JDK提供的注解(源码注解)
- 自定义注解
- 元注解
注解的用处
- 降低项目的耦合
- 自动完成一些规律性代码
- 自动生成java代码,减少开发工作量
注解器
注解器通常是以Java代码(或者编译过的字节码)作为输入,生成.java文件作为输出
AbstractProcessor
1 | // 源于javax.annotation.processing; |
自定义注解
如果是单一属性,可以使用value字段
1 | MyAnno1 { |
如果不是value字段的话,需要(指定属性 = 值)
注解中只允许八种基本数据类型、字符串、类类型,注解类型,枚举类型及其一维数组
Glide和Picasso
简述LruCache和DiskLruCache
内部都实现了LRU算法,即:优先淘汰那些最近最少使用的缓存对象
LruCache:
内部采用LinkedHashMap,是线程安全的(get、put、remove方法都是用synchronized),双向链表(保持LinkedList规定顺序+HashMap便于查找)
将最近使用的节点放置在链表尾部,当超过大小时,删除第一个头节点。
存储了前一个元素和后一个元素的引用,get方法后,就查出值删除,然后放置在头部,如果超过Lru算法的大小,直接遍历删除尾节点,直到大小在范围内
简述Glide的缓存过程
默认打开缓存,内存缓存使用LruCache+弱引用实现,磁盘缓存使用DiskLruCache实现
使用内存缓存+磁盘缓存的策略,生成key时,图片只要发生变化,就算长宽发生变化也会导致缓存不同的key。Glide将内存缓存划分为两个区域:
- LruResourceCache:使用LruCache算法,LinkedHashMap(不在使用的)
- activeResources:添加弱引用机制,HashMap(正在使用的图片)
磁盘缓存之存在DiskLruCache,因为Glide可以压缩图片(尺寸压缩),所以磁盘缓存中可以设置缓存原始图片还是压缩后的图片,压缩图片可以有效避免大图和超大图带来的OOM,Glide没有使用google提供的DiskLruCache,而是使用自己开发的,不过原理都一样
在首次访问时,将正在使用的图片信息会存储在activeResources的弱引用中,当引用次数为0时(调用release方法),会将其放入LruResourceCache中,执行Lru算法,移除后会存入DiskLruCache中。
所以,先去activeResources中寻找,找到后,将引用对象索引+1(active.aquire();)(计算引用次数)。然后去LruResourceCache中寻找了,若找到了,在LruResourceCache中移除,并将其放入activeResources中。然后去DiskLruCache中寻找,若找到了,在DiskLruCache中删除,并将其放入activeResources中。
Glide 缓存的是imageView的所需图片的大小,若大小不同,重新缓存
Picasse 缓存图片原图大小
Glide是如何绑定生命周期的?
- Application参数:如果传入的是Application对象,那么这里就会调用带有Context参数的get()方法重载,调用getApplicationManager()方法来获取一个RequestManager对象。其实这是最简单的一种情况,因为Application对象的生命周期即应用程序的生命周期,因此Glide并不需要做什么特殊的处理,它自动就是和应用程序的生命周期是同步的,如果应用程序关闭的话,Glide的加载也会同时终止。
- 非Application参数:不管传入的是Activity、FragmentActivity、v4包下的Fragment、还是app包下的Fragment,最终的流程都是一样的,那就是会向当前的Activity当中添加一个隐藏的Fragment。因为Glide需要知道加载的生命周期。很简单的一个道理,如果你在某个Activity上正在加载着一张图片,结果图片还没加载出来,Activity就被用户关掉了,那么图片还应该继续加载吗?当然不应该。可是Glide并没有办法知道Activity的生命周期,于是Glide就使用了添加隐藏Fragment的这种小技巧,因为Fragment的生命周期和Activity是同步的,如果Activity被销毁了,Fragment是可以监听到的,这样Glide就可以捕获这个事件并停止图片加载了。
- 如果我们是在非主线程当中使用的Glide,那么不管你是传入的Activity还是Fragment,都会被强制当成Application来处理。
- RequestManagerFragment:实现一个无UI的fragment。
- ActivityFragmentLifecycle:无UI的fragment通过它,去调用RequestManager
- RequestManager:实现关键的几个方法,去调用glide 的操作
- RequestManagerRetriever:作为一个桥梁,将RequestManagerFragment
和RequestManager给联系起来
空RequestManagerFragment 的生命周期调用 ActivityFragmentLifecycle,然后ActivityFragmentLifecycle 调用 RequestManager ,RequestManager 再去调用RequestTracker 的glide操作,最终实现gilde的操作,能够根据页面的生命周期做相应的处理。
Glide中Fragment中是怎么绑定生命周期的?
Glide中into指定view,再次刷新view会发生什么?
Glide内部通过HttpUrlConnection进行通信,也可切换为okhttp/volley
- 根据ScaleType进行相应的设置
- 根据传入的类型对Glide加载进行配置,asBitmap,asGif,asDrawable
- 根据target(View)创建Request请求,根据生命周期管控Request的暂停和下载
target就是view,先判断target是之前已经绑定了请求,如果旧请求和新请求一样且处于请求完成或者正在请求状态就直接复用旧请求。如果不复用,就RequestManager先移除和旧请求绑定的target对象,Target再重新和Request对象进行一个绑定,调用requestManager.track(target, request)再加入请求队列,开启请求,最后返回经过处理的traget对象。
Glide和Picasso对比
- Glide较Picasso庞大的多
- Glide绑定生命周期,onPause时暂停加载,onResume时再启动,Picasso只存在context
- Glide会缓存imageView图片大小,尺寸不同,key不同,会缓存两份,Picasso是缓存完整大小,使用时会重新设置大小
- Glide首次加载快于Picasso,而后每次加载慢于Picasso,因为Glide需要改变图片的大小再缓存到内存,时间会慢。picasso拿到缓存后需要对图片重新设置大小,耗时较长。
- Glide支持gif
- Glide加载的图片质量略差,因为bitmap的格式内存开销小,但是很难察觉
- Glide可以配置图片显示的动画,而picasso只有默认的一种动画
- Glide缓存方式更优,减少OOM的发生
Glide:RGB565
Picasso:ARGB8888
Picasso
缓存机制:LruCache,DiskLruCache
内存缓存占用一个app的15%内存
网络请求使用的okhttp,内部缓存也使用okhttp,一般大小不超过50M
网络机制:network
Fresco比较
缓存机制:
分层处理,producer层层处理,每层处理结果通过Consumer向上传递,Producer-consumer链
- 从已编码缓存中获取bitmap缓存
- 从未编码缓存中获取EncodedImage类型
- 从磁盘中获取
- 从网络中获取
DraweeView:
动图播放,多级图层,渐进显示,画面剪裁
- 解码器优化,避免频繁解码导致内存抖动,使用pool内存池复用
适合各个android版本的解码器
优点:
- 内存管理,LRU算法,缓存和磁盘管理
- 加载大图和高清图时可以先加载低清晰度图和缩略图
- 加载gif
- 图片渐进式处理:,渐进式图片格式先呈现大致的图片轮廓,然后随着图片下载的继续,呈现逐渐清晰的图片
包体积
Fresco>Glide>Picasso
LeakCanary
检测内存泄漏
ActivityLifecycleCallbacks 与 FragmentLifeCycleCallbacks
通过application.registerActivityLifecyleCallbacks获取Activity的生命周期
通过fragmentManager.registerFragmentLifecyleCallbacks获取Fragment的生命周期
注册接口,拿到Activity和Fragment的各种生命周期回调信息
如何做到内存泄漏检测
Activity在onDestory后会将Activity生成一个唯一的key后存储在弱引用队列中,在主线程空闲时(IdleHandler)触发gc机制,垃圾回收,整理弱引用队列,查看弱引用队列中没有被回收的对象,即是内存泄漏的对象,打印出栈堆信息以供分析dump
缺陷
只能监听Activity和Fragment的内存泄漏检测,无法检测Service
其他内存泄漏检测工具
Profiler:android studio自带,可以查看内存的整体过程,分析是否发生内存泄漏
ASM函数插桩
简述
简析为字节码插桩,可以直接修改已经存在的class文件或者生成class文件,相比较于AspectJ,ASM更加偏向于底层,他是直接操作字节码的,在设计中更小,更快
class文件本质是16进制数据
ClassVisitor
MethodVistor
Android基础篇
Application
简述Application
作用:做初始化工作,提供上下文。继承自ContextWarpper,获取的是ContextWrapper中的context对象
- 一个应用中有且只有一个
- 其生命周期和应用程序一样长
- Application的onCreate方法才是整个应用程序的入口
- 只会实例化一次,所以天生就是一个单例
生命周期:
- onCreate:创建时执行
- onTerminate:终止时执行
- onLowMemory:低内存时执行
Application的初始化流程
通过AMS协调,ActivityThread优先建立后,会新建一个ApplicationThread,用作和AMS通过Binder通信,之后AMS通知ActivityThread去bindApplication,将消息返送到messageQueue,进行初始化Application的任务,然后调用attachBaseContext将Context绑定到Application,最后调用Application.onCreate()方法进行后续Activity的初始化
AMS 来通知 zygote 进程来 fork 一个新进程,来开启我们的目标 App 的
ActivityLifecycleCallbacks理解
ActivityLifecycleCallback是Application中的一个接口,可以监听应用中所有Activity的生命周期,可以通过该方法完成一些特殊的需求,比如监测当前App显示的Activity是那个?App是否存在前台
1 | public class MyApplication extends Application { |
Activity
简述生命周期

Activity:
- onCreate() 正在被创建
- onRestart() 不可见到可见
- onStart() Activity正在启动,已经可见了
- onResume() Acitivty已经可见,并在前台显示
- onPause() Acitivty正在停止,之后会不可见
- onStop() Activity即将停止
- onDestory() Activity被销毁
onStart和onResume都为可见,onStart不在前台显示,onResume在前台显示
onPause后已经不可见,会进入onResume或者另一个onResume,所以不能做耗时操作,会影响界面显示
onPause和onStop中不能太耗时
如果新的Activity采用了透明主题,那么当前Activity不会回调onStop
onStart和onStop对应Activity是否可见
onResume和onPause对应Activity是否在前台显示
异常情况下会执行onSaveInstance方法进行数据保存
简述启动模式
- standard:标准模式,来一个添加一个
- singleTop:栈顶复用,如果在栈顶,就复用这个Activity,
onNewIntent会被执行,替代onCreate() - singleTask:栈内复用,如果在栈内,就复用这个Activity,该Activity之上的全部出栈,onNewIntent会被执行
- singleInstance:单实例模式。加强版singleTask,会为自己新建一个栈,在该栈中栈内复用
LauncherMode和startActivityForResult
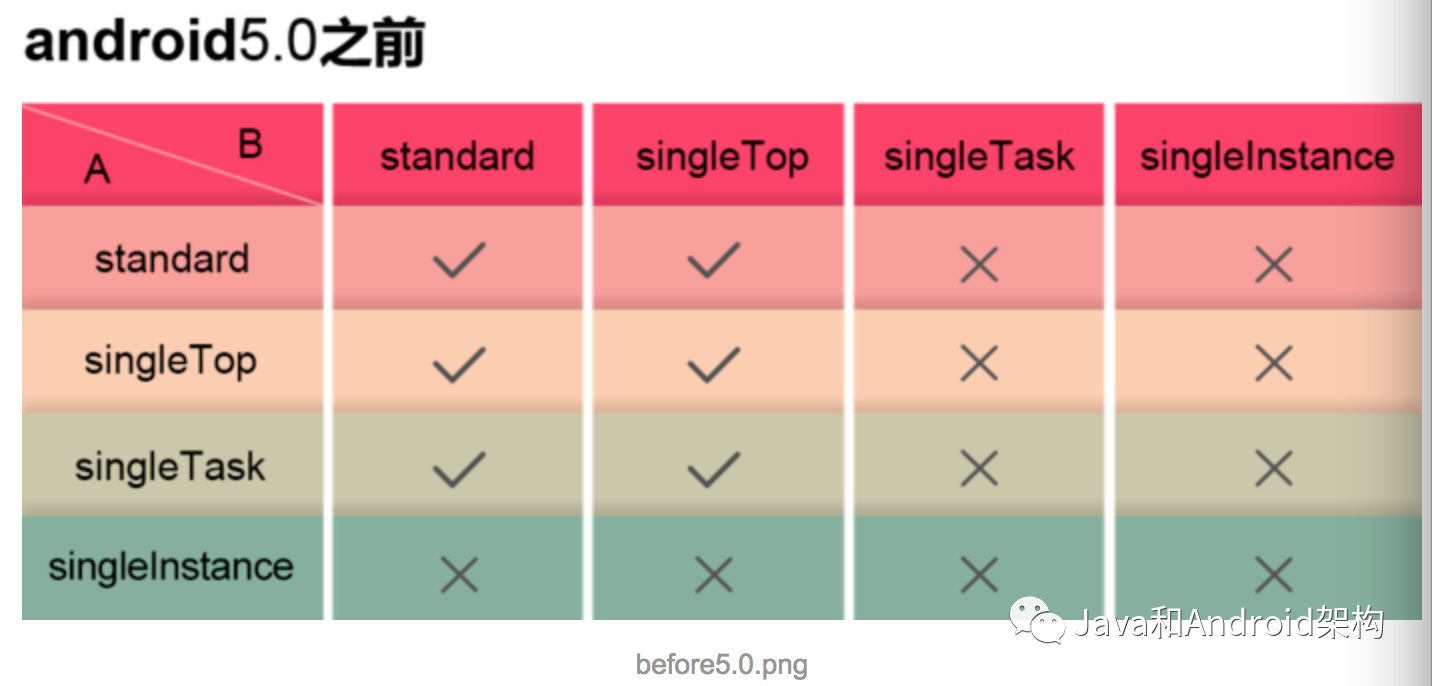
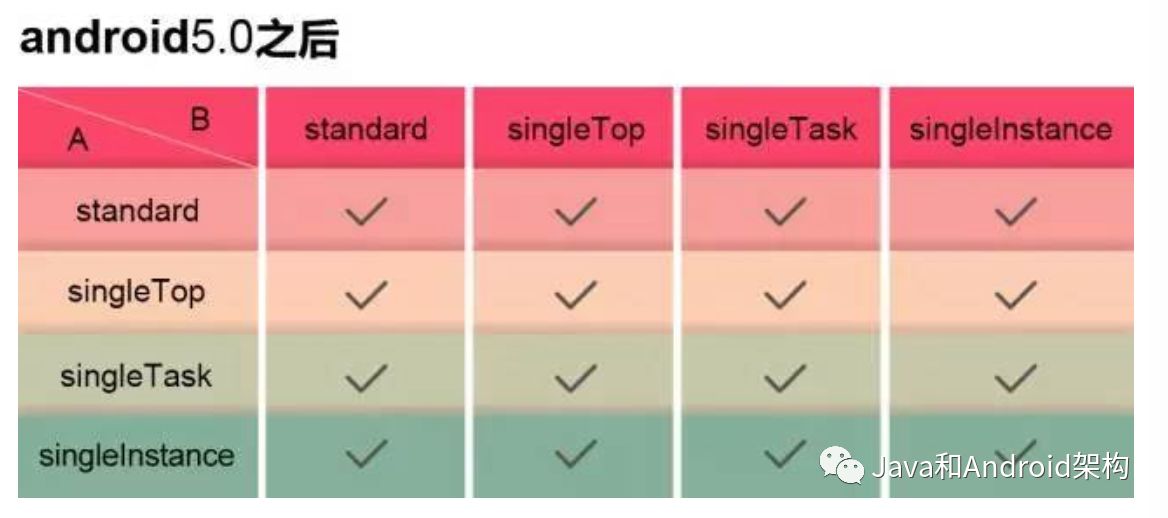
在5.0之前,当启动一个Activity时,系统将首先检查Activity的launchMode,如果为A页面设置为SingleInstance或者B页面设置为singleTask或者singleInstance,则会在LaunchFlags中加入FLAG_ACTIVITY_NEW_TASK标志,而如果含有FLAG_ACTIVITY_NEW_TASK标志的话,onActivityResult将会立即接收到一个cancle的信息,而5.0之后这个方法做了修改,修改之后即便启动的页面设置launchMode为singleTask或singleInstance,onActivityResult依旧可以正常工作,也就是说无论设置哪种启动方式,StartActivityForResult和onActivityResult()这一组合都是有效的
什么时候会启动一个新的Activity栈?
- allowTaskReparenting:
- singleInstance单独使用,会新建一个栈
- singleTask配合taskAffinity使用
- taskAffinity配合Intent.FLAG_ACTIVITY_NEW_TASK修饰Activity(AMS先处理LauncherMode,在处理FLAG_ACTIVITY_NEW_TASK)
- taskAffinity配合allowTaskReparenting属性,使Activity从启动栈移动到正在使用的栈中并显示出来
如何控制Activity的动画切换
- 通过overridePendingTransition(R.anim.slide_in_right, R.anim.slide_out_left)方法控制
再startActivity方法后或者finish方法之后调用即可生效 - 使用style定义切换动画
如何控制Fragment的动画切换
1 | FragmentTransaction fragmentTransaction = mFragmentManager |
使用FragmentTransaction开启Fragment动画,设置自定义动画切换,进入动画和推出动画
ActivityA跳转到ActivityB,再按back键返回ActivityA,生命周期情况?
ActivityA跳转到ActivityB:onPauseA()—–>onCreateB()—–>onStartB()—–>onResumeB()—–>onStopA()
ActivityB按back键返回ActivityA:
onPauseB()—–>onRestartA()—–>onStartA()—–>onResumeA()—–>onStopB()—–>onDestoryB()
如果ActivityB是窗口Activity呢?
ActivityA跳转到ActivityB:onPauseA()—–>onCreateB()—–>onStartB()—–>onResumeB()
ActivityB按back键返回ActivityA:onPauseB()—–>onResumeA()—–>onStopB()—–>onDestoryB()
Activity的生命周期会受Dialog影响吗?
不会,Activity生命周期不会随Dialog的显示而变化
Activity的生命周期受AMS调用,而dialog不是Activity,所以不受AMS控制,所以不会触发Activity的生命周期
Service
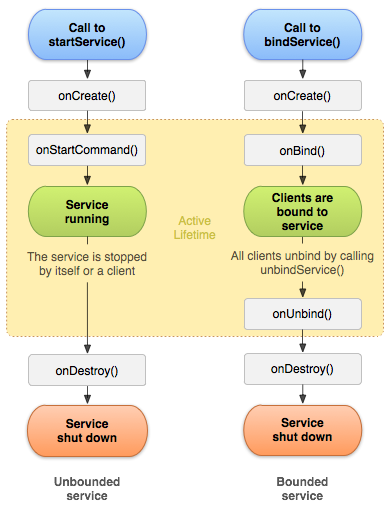
Service有几种创建方式?有什么区别?
- startService(),在不需要的时候stopService()
- bindService(),与生命周期相绑定,在销毁的时候进行回收unbind()
如何理解IntentService?生命周期是什么?HandlerThread 是什么?
intentService继承自Service,持有Service的功能,同时,他是一个处理异步操作的类,当异步执行结束后会自动关闭intentService,多次执行startService(),只是执行onStartCommand方法,将消息加入到消息队列中。
其本质就是启动了一个类似于主线程Handler的机制去维护异步操作。
生命周期:onStartCommand()中执行onStart()方法,在onstart()方法中添加handler.sendMessage()方法
HandlerThread:就是将Handler+looper进行封装,允许直接在子线程中使用handler的一套逻辑。
IntentService更像是一个后台线程,但是他又是一个服务,不容易被回收,这是他的优点
JobIntentService
是IntentService的子类,在android 8.0(26)以上,IntentService的所有后台执行任务都会受到限制约束,所以要使用JobIntentService。
service不能使用后台服务,需要使用ContextCompat.startForegroundService启动前台服务,这样就会启动一个notification,对用户来说体验不是很好,所以就要使用
JobIntentService启动一个后台服务
在使用JobIntentService的时候不需要startService,stopService,在需要的时候调用1
DownLoadJobIntentService.enqueueWork(MainActivity.this,DownLoadJobIntentService.class,jobId(8),intent);
而后会执行onHandleWork方法中的逻辑,执行完毕后自动销毁
onStartCommand中三个回调分别是什么?
- START_NOT_STICKY:Service被回收后不做处理
- START_STICKY:Service在被回收后,重新创建Service,但是
不保存intent - START_REDELIVER_INTENT:Service在被回收后,重新创建Service,
保存intent - START_STICKY_COMPATIBILITY:START_STICKY的兼容版本,但不保证服务被kill后一定能重启。
Service保活
- 设置成前台服务,绑定Notification, startForeground(1, getNotification());
- 单独设置为服务进程
- onStartCommand返回START_STICKY,START_REDELIVER_INTENT,保证服务被干掉后重启
- 在onDestory发送一个广播,广播接收器接收广播后拉起服务
- 添加系统广播拉起
- 提升服务的优先级
Fragment
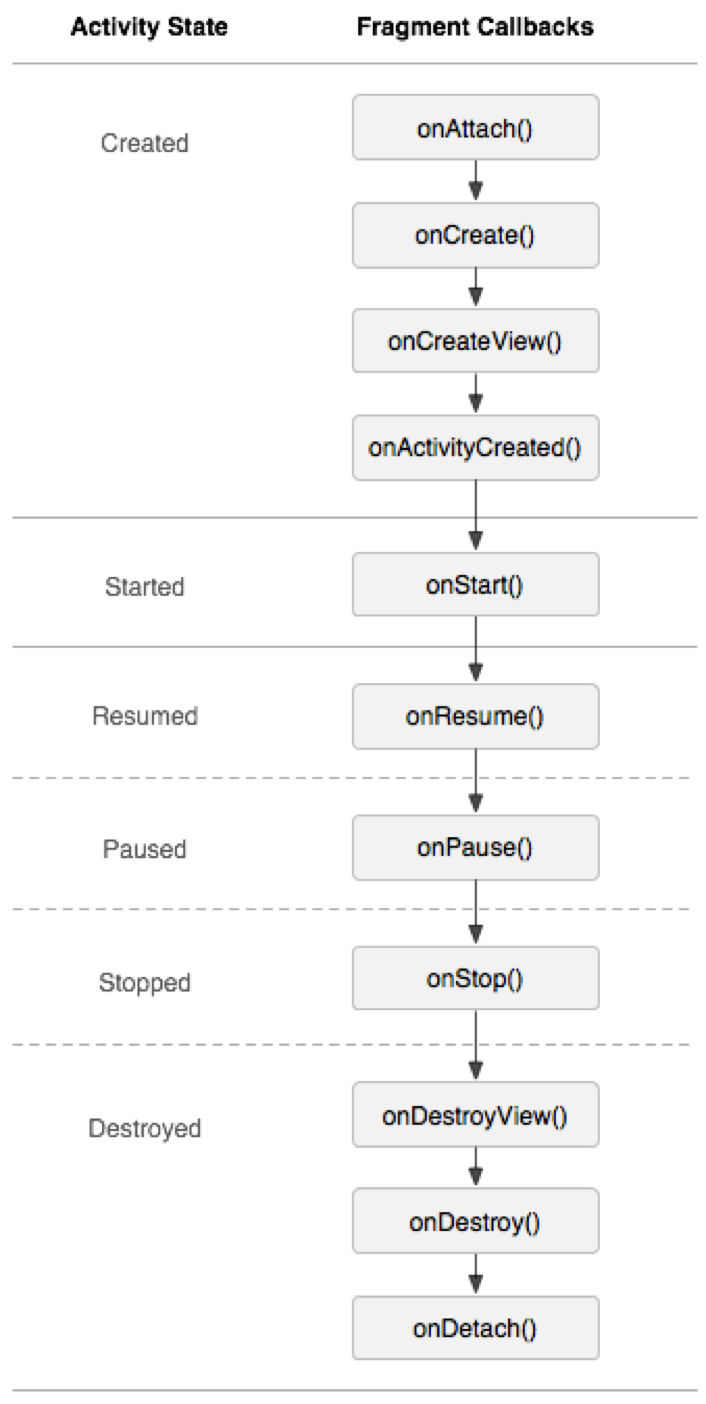
生命周期
FragmentPagerAdapter和FragmentStatePagerAdapter的区别?
FragmentPagerAdapter:切换页面只是将Fragment分离,适合Fragment较少的情况不影响内存
FragmentStatePagerAdapter:切换页面将Fragment回收,适合Fragment较多的情况,这样不会消耗太多内存资源
Fragment的3种切换方式
- add方法:只是重新回到fragment
- replace方法:每次都会重新构建fragment
为什么不能用Fragment的构造函数进行传参?有什么劣势,应该怎么办?为什么?
Fragment在异常崩溃后重建时,默认会调用Fragment无参构造,这样会导致Fragment中的有参构造的值不会被执行,这样数据就会异常
Fragment中调用setArguments来传递参数,在Activity构造Fragment时会通过反射午餐构造实例化一个新的Fragment,并且给mArguments初始化为原先的值
Fragment的重建在那个生命周期中?
在FragmentActivity的onSaveInstanceState中做存储,将Framgent通过序列化Parcelable进行存储,在Activity的onCreate中进行恢复
当配置发生变化时,Activity进入销毁过程,FragmentManager先销毁队列中Fragment的视图,然后检查每个Fragment的retainInstance属性。如果retainInstance为false,FragmentManager会销毁该Fragment实例;如果retainInstance为true,则不会销毁该Fragment实例,Activity重建后,新的FragmentManager会找到保留的Fragment并为其创建视图。
BroadCastReceiver
简述广播的启动方式和区别
- 静态注册:在AndroidManifest中注册,常驻型广播
- 动态注册:使用intentFilter过滤广播,registerReceiver注册广播,跟随生命周期
Android8.0以上部分广播不允许静态注册
无序广播和有序广播的区别
- 无序广播:所有广播接收器都可以获得,不可以拦截,不可以修改
- 有序广播:按照优先级向下传递,可拦截广播,修改广播
本地广播和全局广播
本地广播接收器只接收本地广播,减少应用外广播干扰,高效
androidx中1.1.0-alpha01中弃用本地广播,官方推荐该用LiveData或响应式流
IPC机制
简述android中的IPC机制
进程间通信
架构:Client/Server架构,Binder机制,之间通过代理接口通信
client,server,serverManager
AndroidManifest中指定Android:process属性
- 包名:remote为应用私有进程,其他应用不可访问
- 包名.remote为全局进程,其他应好通过ShareUID可以和他跑在同一个进程
多进程带来的问题:四大组件共享数据失败,每个进程会单独开辟内存空间存储信息
- 静态成员和单例模式完全失效
- 线程同步机制完全失效
- SharedPreferences可靠性下降,不支持多进程
- Application会多次创建
Serializable和parcelable区别
serializable:java自带,反射后产生大量临时变量,容易引起gc,主要用于持久化存储和网络传输的序列化
parcelable:android专用,性能强,将完整对象分解为部分对象,每一部分进行intent传输,可用于ipc,内部实现Bundle,主要用于内存的序列化
Android为什么引入Parcelable?
- serializable通过反射,性能不好,
- serializable反射产生大量临时变量,容易gc,导致内存抖动
- serializable使用了大量的IO操作,也影响了耗时
parcelable使用复杂,但高效,适用于内存序列化
Parcelable一定比Serializable快吗?
单论内存中的传输速度,Parcelable一定快于Serializable,但是Parcelable没有缓存的概念
Serializable存在缓存,会将解析过的内容放置在HandleTable,下次解析到同一类型的对象时就可以直接复用
为什么java使用Serializable序列化对象,而不是json或者xml?
因为历史遗留问题,在json和xml出来之前,java已经设计了Serializable,对于Java的庞大体系,并不容易修改这个问题。java官方文档也推荐使用json库,因为他简单、易读、高效
简析Binder机制
在Android通信中并不是所有的进程通信都使用Binder,当fork()进程时,使用的是Socket()通信,因为fork不允许多线程,Binder是多线程模式,所以不被允许
进程空间划分
一个进程空间分为用户空间和内核空间
用户空间:数据独享,其他进程无法访问
内核空间:数据共享,其他进程可以访问
所有的进程共用1个内核空间
如何看待ServiceManager?
ServiceManager管理系统中所有的服务,服务需要使用时都要在ServiceManager中进行注册,他的存在类似于DNS,提供client访问某一个服务的查询。
Binder原理
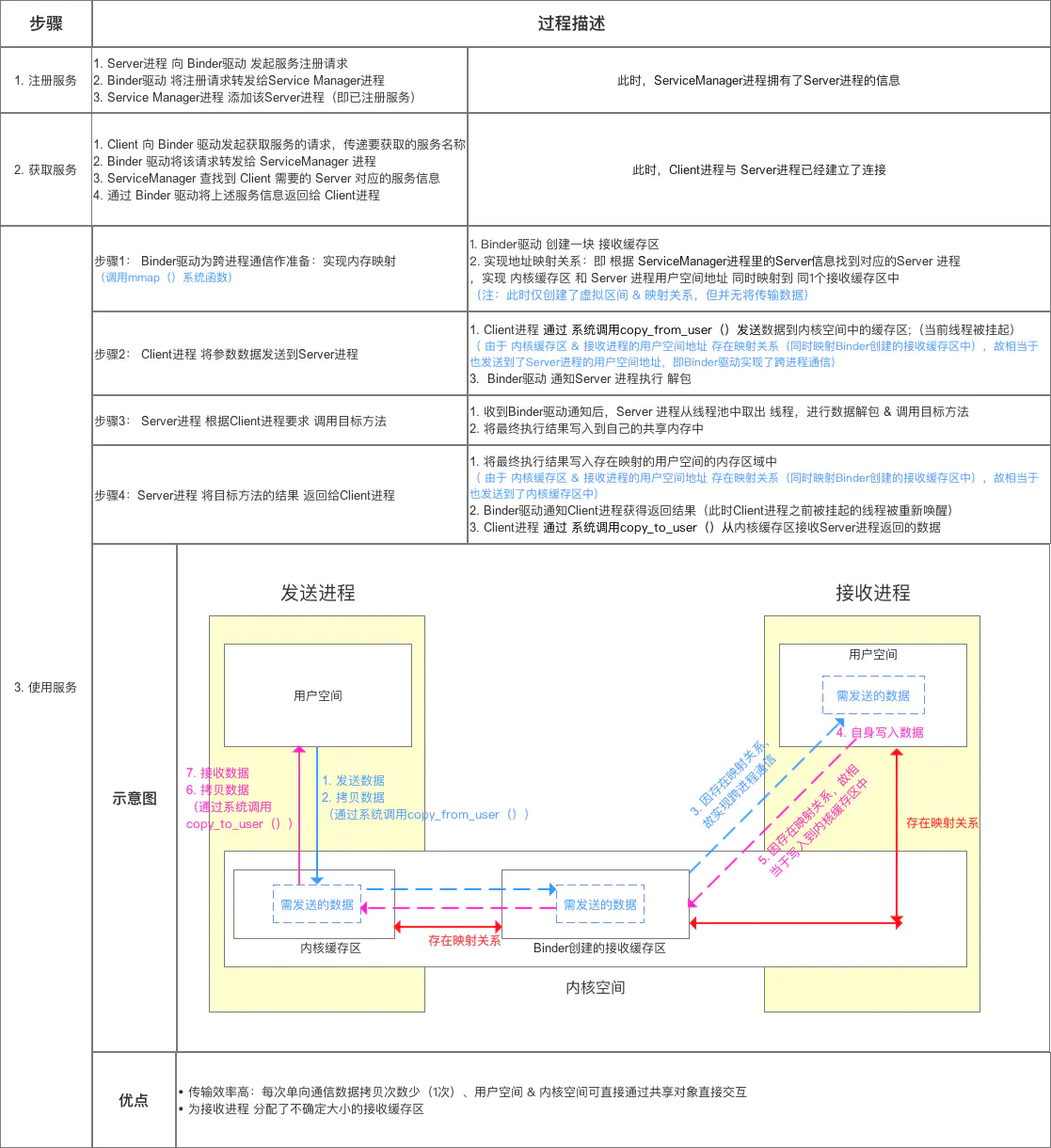
binder驱动属于进程中的内核空间,即共享空间,在client发起请求时,需要将数据从用户空间拷贝到内核空间,binder通过传输内核空间中数据存储的引用映射给服务端,供服务端调用,服务端处理后,将返回值放在内核空间,通过binder传递引用映射给客户端进行处理
简述通信流程
总体通信流程就是:
- 客户端通过代理对象向服务器发送请求。
- 代理对象通过Binder驱动发送到服务器进程
- 服务器进程处理请求,并通过Binder驱动返回处理结果给代理对象
- 代理对象将结果返回给客户端。
详细的通信过程
- 服务端跨进程的类都要继承Binder类,所以也就是服务端对应的Binder实体。这个类并不是实际真实的远程Binder对象,而是一个Binder引用(即服务端的类引用),会在Binder驱动里还要做一次映射。
- 客户端要调用远程对象函数时,只需把数据写入到Parcel,在调用所持有的Binder引用的transact()函数
- transact函数执行过程中会把参数、标识符(标记远程对象及其函数)等数据放入到Client的共享内存,Binder驱动从Client的共享内存中读取数据,根据这些数据找到对应的远程进程的共享内存。
- 然后把数据拷贝到远程进程的共享内存中,并通知远程进程执行onTransact()函数,这个函数也是属于Binder类。
- 远程进程Binder对象执行完成后,将得到的写入自己的共享内存中,Binder驱动再将远程进程的共享内存数据拷贝到客户端的共享内存,并唤醒客户端线程。
通过Binder将客户端,服务端的共享内存中的数据进行读写,放入对方的共享内存中,并通知。
Binder在Android中的应用?
- 系统服务及四大组件的启动调用工作:系统服务是通过getSystemService获取的服务,内部也就是通过ServiceManager。例如四大组件的启动调度等工作,就是通过Binder机制传递给ActivityManagerService,再反馈给Zygote。而我们自己平时应用中获取服务也是通过getSystemService(getApplication().WINDOW_SERVICE)代码获取。
- AIDL(Android Interface definition language)。例如我们定义一个IServer.aidl文件,aidl工具会自动生成一个IServer.java的java接口类(包含Stub,Proxy等内部类)。
- 前台进程通过bindService绑定后台服务进程时,onServiceConnected(ComponentName name, IBinder service)传回IBinder对象,并且可以通过IServer.Stub.asInterface(service)获取IServer的内部类Proxy的对象,其实现了IServer接口。
为什么选择Binder机制?他的优势是什么?
- 性能高,效率高:
传统的IPC(socket,管道,消息队列)需要拷贝两次内存,Binder只需要拷贝一次内存、共享内存不需要拷贝数据,只需要传递引用 - 安全性好:
C/S通信添加UID/PID,方便验证,安全机制完善。 - 利用C/S架构,通过多线程控制一个服务端多个客户端的情况
Android中IPC的几种方式详细分析与优缺点分析
- Bundle
- 文件共享
- Messenger:内部实现AIDL机制,c/s架构,通过handler接收message对象
- AIDL
- ContentProvider
- Binder连接池
Handler
其实并不是每一次添加消息时,都会唤醒线程。当该消息插入到队列头时,会唤醒该线程;如果有延迟消息,插入到头部,也会唤醒线程后在休眠
一句话概括Handler,并简述其原理
android中用于主线程和子线程之间通信的工具
主要包含Handler,Looper,MessageQueue,ThreadLocal.
Handler:封装了消息的发送和接收looper分发过来的Message
Looper:协调Handler和MessageQueue之间的桥梁,Looper的作用是循环从MessageQueue中取出message,并分发
给相应的Handler,Handler则存储在Message中的target中
message:单节点,存储handler传输的数据
MessageQueue:内部结构为单链表,由Looper创建,具体代码为Looper.prepare();先进先出原则(队列),根据 Message.when进行插入队列(队列中是按时间执行顺序排序)
ThreadLocal:负责存储和获取本线程的Looper
handler.sendMessage(message)将message发送到MessageQueue,MessageQueue执行enqueueMessage()方法入队,Looper执行looper.loop()方法从MessageQueue中取出message,执行message.target.dispatchMessage(message)方法将消息发送到Handler中,在handleMessage()方法中拿到回调
Looper.loop()是在主线程的死循环,为什么没有造成线程阻塞?
真正的ANR是在生命周期的回调中等待的时间过长导致的,深层次的讲,就是Looper.loop()没有及时取出消息进行分发导致的。一旦没有消息,Linux的epoll机制则会通过管道写文件描述符的方式来对主线程进行唤醒与沉睡,Android里调用了linux层的代码实现在适当时会睡眠主线程。
MessageQueue包含jni调用,无消息时,通知epoll休眠,来消息时,线程启动
looper.loop()中循环,判空退出怎么理解?
1 | public static void loop() { |
在queue.next中,会通过jni调用,通过Linux的epoll机制则会通过管道写文件描述符的方式来对主线程进行唤醒与沉睡,只有当应用程序退出时,才会执行if语句退出循环。
为什么不能在子线程更新UI?
因为如果要在子线程中更新UI,势必要考虑线程安全,加锁机制,这样很耗时,不加锁又很容易发生错误,这些错误是致命的,所以在设计时只允许UI线程更新UI,避免这些错误。
真的不能在子线程更新UI吗?
ViewRootImpl中会进行通过checkThread()进行线程检测
1 | public ViewRootImpl(Context context, Display display) { |
由此得出:viewRootImpl在那个线程被初始化,就会在那个线程更新UI,大部分情况下,ViewRootImpl都是在UI线程中初始化的,所以只能在UI线程更新UI,部分情况下可以在子线程更新UI(比如Dialog是在addView中初始化ViewRootImpl)
SurfaceView可以在子线程中更新
ViewRootImpl是什么时候被创建的?
在Acitivty中,ViewRootImpl是在onResume中创建的,所以在onCreate中进行子线程更新是可以绕过checkThread()检测的。
一个Thread中可以有几个Looper?几个Handler
一个Thread中只有一个Looper,可以存在无数个Handler,但是使用MessageQueue都是同一个,也就是一个Looper
可以在子线程直接new一个Handler吗?那该怎么做?
1 | thread= new Thread(){ |
需要创建Looper,Looper会创建MessageQueue,循环从MessageQueue中取消息。
Message可以如何创建?哪种效果更好,为什么?
享元模式
数据重复利用
- Message msg = new Message();
- Message msg2 = Message.obtain();
- Message msg1 = handler1.obtainMessage();
2,3从整个Messge池中返回一个新的Message实例,通过obtainMessage能避免重复Message创建对象。
所以2,3都可以避免重复创建Message对象,所以建议用第二种或者第三种任何一个创建Message对象。
messge就是一个节点,存在就是一条链表,链表中存储的都是可以复用的message,在handleMessage和callback
方法执行完成后执行message.recycle()方法,进行信息重置后加入闲置链表头部中,每次调用obtain方法会从闲置链表中取出头节点,如果闲置链表为空,则新建message。
Message缓存池大小为50
使用Hanlder的postDelay()后消息队列会发生什么变化?
postDelay()内部调用sendMessageDelayed()
1 | public final boolean sendMessageDelayed(Message msg, long delayMillis) |
时间:SystemClock.uptimeMillis() + delayMillis
SystemClock.uptimeMills()是从开机到现在的时间,不使用currentMills,因为其是可变的,uptimeMills()期间不包括休眠的时间,是一个相对时间
- Handler.postDelayed(Runnable r, long delayMillis)
- Handler.sendMessageDelayed(getPostMessage(r), delayMillis)
- Handler.sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis)
- Handler.enqueueMessage(queue, msg, uptimeMillis)
- MessageQueue.enqueueMessage(msg, uptimeMillis)
消息入队的时候会根据when判断时间,最终按照时间大小排序,时间短的在链表头,时间长的在链表尾部。
案例如下:
postDelay()一个10秒钟的Runnable A、消息进队,MessageQueue调用nativePollOnce()阻塞,Looper阻塞;- 紧接着
post()一个Runnable B、消息进队,判断现在A时间还没到、正在阻塞,把B插入消息队列的头部(A的前面),然后调用nativeWake()方法唤醒线程; MessageQueue.next()方法被唤醒后,重新开始读取消息链表,第一个消息B无延时,直接返回给Looper;- Looper处理完这个消息再次调用
next()方法,MessageQueue继续读取消息链表,第二个消息A还没到时间,计算一下剩余时间(假如还剩9秒)继续调用nativePollOnce()阻塞; - 直到阻塞时间到或者下一次有Message进队;
同步消息、异步消息和同步屏障消息是什么?具体应用场景是什么?
同步消息:handler默认无参构造的形式是同步消息
异步消息:async传入true,则为异步消息
屏障消息:msg.target == null,使用postSyncBarrier()方法打开同步屏障,导致同步消息不执行,优先执行异步消息,规则同同步消息一样,当执行完毕后关闭同步屏障。
应用场景:在view的更新过程中,draw,requestLayout、invalidate中都用到这个方法,系统会优先处理这些异步消息,等处理结束后再处理同步消息。这样可以优先处理我们指定的系统消息。
postSyncBarrier()该方法为私有方法,所以api不允许我们在开发中调用,我们只要知道原理就好了
调用该方法,会直接发送一个屏障消息进入messageQueue,则队列头部为屏障消息
ThreadLocal,谈谈你的理解
跟HashMap功能类似,为什么不直接用HashMap呢?
原因:
- HashMap太大了,太臃肿了。ThreadLocal的key值只有Thread,value为looper,而HashMap的key值则可以
是string、int等数据类型,我们可以不用考虑这些数据类型; - 线程隔离:我们的线程是系统中唯一的,用ThreadLocal来管理这些唯一的线程和其对应的value值会非常方便,
- ThreadLocal参照了HashMap,简化了HashMap,便于我们使用。
- HashMap线程不安全
为什么子线程中不能使用Handler,而UI线程可以?
UI线程就是ActivityThread,他在初始化的时候创建了Looper,MessageQueue,所以可以直接使用Handler,而新创建的子线程没有创建Looper,所以创建了就可以使用了
Handler的构造方法中使用Looper.myLooper()获取了looper,但是在子线程中并没有looper
Handler如何引起内存泄露?怎么解决?
非静态内部类或匿名内部类默认持有外部类的引用,当外部类被回收时,因为内部类持有外部类的引用,导致外部类不能被回收,造成内存泄露。
- Activity销毁时及时清理消息队列;
- 自定义静态Handler类+弱引用。
MessageQueue.next()会因为发现了延迟消息,而进行阻塞。那么为什么后面加入的非延迟消息没有被阻塞呢?
首先非延时消息会入队,并且插入链表头,这时唤醒线程,进行循环取出message,非延时消息出队,到延迟消息后,如果事件未到,触发next的阻塞机制,如果时间到了,取出message,执行消息
Handler延时机制保时吗?
不保时
1 | chatIflyHandler.post(new Runnable() { |
首先一个非延时消息入队,紧接着一个延时消息入队,执行第一个非延时消息,用时3s后执行延时消息,对比when,然后直接执行,测试总共耗时3420ms
Handler的入队机制是线程安全的(synchronized)
1 | messageQueue.equeue(){ |
如何精确计时?
使用timer(子线程处理TimerThread)
误差补偿算法(TextClock控件方法)
1
2
3
4
5
6
7
8
9
10private final Runnable mTicker = new Runnable() {
public void run() {
onTimeChanged();
long now = SystemClock.uptimeMillis();
long next = now + (1000 - now % 1000);
getHandler().postAtTime(mTicker, next);
}
};整秒数执行,当上次执行累积到1200,在下次执行时,通过next的计算后保证下次执行的时间不被累加到2200,而是同样在2000
IdleHandler是什么?用处是什么?
messageQueue中有一个addIdleHandler()方法,添加IdleHandler接口
- 添加时messageQueue不为空,则在线程休眠(没有消息,延时消息)时回掉方法
- 添加时messageQueue为空,则当时不会触发回掉,当线程被唤醒时才会执行
就是在启用IdleHandler的时候,如果线程处于休眠状态,要等到下次休眠状态才会生效。如果不是休眠状态,则下一次休眠立即生效。
启用IdleHandler后,主线程下次休眠时会通知
2
3
4
5
6
7
8
9
public boolean queueIdle() {
//do something
return false;
}
});
如果return true,则表示这个IdleHandler可多次使用
如果return false,则表示这个IdleHandler只能使用一次
主线程的Looper何时退出?能否手动退出?
在app退出或者异常终止时,会退出Looper。在正常退出时,ActivityThread主线程中的mH(Handler)会接收到回调信息,调用quit()方法,强制退出1
2
3
4
5
6
7//ActivityThread.java
case EXIT_APPLICATION:
if (mInitialApplication != null) {
mInitialApplication.onTerminate();
}
Looper.myLooper().quit();
break;
Looper.quit():调用后直接终止Looper,不在处理任何Message,所有尝试把Message放进消息队列的操作都会失败,比如Handler.sendMessage()会返回 false,但是存在不安全性,因为有可能有Message还在消息队列中没来的及处理就终止Looper了。
Looper.quitSafely():调用后会在所有消息都处理后再终止Looper,所有尝试把Message放进消息队列的操作也都会失败。
当尝试在主线程手动退出looper时,会报错:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Caused by: java.lang.IllegalStateException: Main thread not allowed to quit.
at android.os.MessageQueue.quit(MessageQueue.java:428)
at android.os.Looper.quit(Looper.java:354)
at com.jackie.testdialog.Test2Activity.onCreate(Test2Activity.java:29)
at android.app.Activity.performCreate(Activity.java:7802)
at android.app.Activity.performCreate(Activity.java:7791)
at android.app.Instrumentation.callActivityOnCreate(Instrumentation.java:1299)
at android.app.ActivityThread.performLaunchActivity(ActivityThread.java:3245)
at android.app.ActivityThread.handleLaunchActivity(ActivityThread.java:3409)
at android.app.servertransaction.LaunchActivityItem.execute(LaunchActivityItem.java:83)
at android.app.servertransaction.TransactionExecutor.executeCallbacks(TransactionExecutor.java:135)
at android.app.servertransaction.TransactionExecutor.execute(TransactionExecutor.java:95)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:2016)
at android.os.Handler.dispatchMessage(Handler.java:107)
at android.os.Looper.loop(Looper.java:214)
at android.app.ActivityThread.main(ActivityThread.java:7356)
at java.lang.reflect.Method.invoke(Native Method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:492)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:930)
因为主线程退出意味着app的关闭,这种操作不和规范,需要使用正式的退出操作
如何退出app
- 记录Activity任务栈,全部finish
- System.exit(0);//正常退出
System.exit(1);//非正常退出 - android.os.Process.killProcess(android.os.Process.myPid()); 关闭进程,如果系统发现进程未正常关闭,会重新启动进程
- 在Intent中直接加入标识Intent.FLAG_ACTIVITY_CLEAR_TOP,这样开启B时,会清除该进程空间的所有Activity。
2.2版本之前使用ActivityManager关闭
1
2ActivityManager am = (ActivityManager)getSystemService (Context.ACTIVITY_SERVICE);
am.restartPackage(getPackageName());2.2版本以后
1
2
3ActivityManager am = (ActivityManager)getSystemService (Context.ACTIVITY_SERVICE);
am.killBackgroundProcesses(getPackageName());
System.exit(0);该方法只是结束后台进程的方法,不能结束当前应用移除所有的 Activity。如果需要退出应用,需要添加System.exit(0)方法一起使用,并且只限栈内只有一个Activity,如果有多个Activity时,正如上面 方法 2 所说,就不起作用了。
将MainActivity设置为singleTask,返回MainActivity后会清空所有的Activity,这样直接在MainActivity执行finish()方法即可
如何看待sendMessageAtFrontOfQueue()
1 | public final boolean sendMessageAtFrontOfQueue(Message msg) { |
传入的延迟时间为0,头插入消息队列,即消息队列下一次立即执行的消息,
如何看待Handler构造中的CallBack方法?
1 |
|
由源码可以看出构造函数中传入Callback参数,调用dispatch方法时,会优先调用callback方法,在调用handleMessage方法,即
Callback接口可以在handleMessage前收到消息,如果返回true,则不会调用handleMessage方法
我们可以利用 Callback 这个拦截机制来拦截 Handler 的消息!
Looper.prepareMain()和Looper.perpare的区别?
区别是一个boolean值,主线程的looper永不退出,除非调用
AsyncTask
如何理解AsyncTask?
- 必须创建在主线程
AscncTask内部封装了Handler+线程池
包含两个线程池,一个是用来排队的 ,一个才是真正的执行,通过Handler将状态回掉到主线程
- 核心线程数,最少两个,最多四个
- 最大线程数= cpu核心数*2+1
- 核心线程无超时限制,非核心线程在闲置时的超时时间为1s
- 任务队列容量为128
execute方法执行,加入排队线程池排队,等待任务执行后通过handler通知主线程,调用状态回调方法,内部实现因为排队线程池阻塞,导致任务是串行的,即同时只有一个任务会进入线程池执行
executeOnExecutor执行调用异步操作
谷歌为何弃用AsyncTask
- 使用多线程更加复杂,使bug难以定位
- 太过复杂
- 滥用继承,effic java推荐“使用组合而不是继承”,使类多,且低效
- 默认的THREAD_POOL_EXECUTOR线程池配置不太合适
线程池
简述线程池
android中线程池主要实现是ThreadPoolExecutor
参数:
- 核心线程数:如果指定ThreadPoolExecutor的allowCoreThreadTimeOut这个属性为true,那么核心线程如果不干活(闲置状态)的话,超过一定时间,就会被销毁掉
- 最大线程数: = 核心线程数 + 非核心线程数
- 超时时间:非核心线程的闲置超时时间
- 超时时间单位:非核心线程的闲置超时时间单位
- 线程等待队列:当所有的核心线程都在干活时,新添加的任务会被添加到这个队列中等待处理,如果队列满了,则新建非核心线程执行任务
- 线程创建工厂:线程池的拒绝策略,可以出错,也可以顾虑
allowCoreThreadTimeOut设置为true,非核心线程超时时间同样用于核心线程,如果为false,核心线程永远不会终止
SynchronousQueue(空集合):这个队列接收到任务的时候,会直接提交给线程处理,而不保留它,如果所有线程都在工作怎么办?那就新建一个线程来处理这个任务!所以为了保证不出现<线程数达到了maximumPoolSize而不能新建线程>的错误,使用这个类型队列的时候,maximumPoolSize一般指定成Integer.MAX_VALUE,即无限大
LinkedBlockingQueue(大小无限):这个队列接收到任务的时候,如果当前线程数小于核心线程数,则新建线程(核心线程)处理任务;如果当前线程数等于核心线程数,则进入队列等待。由于这个队列没有最大值限制,即所有超过核心线程数的任务都将被添加到队列中,这也就导致了maximumPoolSize的设定失效,因为总线程数永远不会超过corePoolSize
ArrayBlockingQueue(大小可以设置):可以限定队列的长度,接收到任务的时候,如果没有达到corePoolSize的值,则新建线程(核心线程)执行任务,如果达到了,则入队等候,如果队列已满,则新建线程(非核心线程)执行任务,又如果总线程数到了maximumPoolSize,并且队列也满了,则发生错误
DelayQueue(延迟出队,大小可以设置):队列内元素必须实现Delayed接口,这就意味着你传进去的任务必须先实现Delayed接口。这个队列接收到任务时,首先先入队,只有达到了指定的延时时间,才会执行任务
规则:
- 未达到核心线程数,新建核心线程
- 达到或者大于核心线程数,任务被插入任务队列等待执行
- 步骤2中无法插入队列(队列满了),线程数量小于线程池最大值,启动一个非核心线程执行任务
- 步骤3 中线程数量达到最大值,则拒绝执行此任务
android主要分为几种线程池?
四种
FixedThreadPool:全是核心线程,没有超时机制,任务队列没有大小限制
CachedThreadPool:全是非核心线程,最大为Integer.MAX_VALUE,空闲线程60s超时(60s内可以复用,60s后回收),适用于执行短时的大量任务,空闲时也不占用cpu资源
ScheduledThreadPool:核心线程固定,非核心线程为Interger.MAX_VALUE,非核心线程无超时机制(执行完就被回收),适用执行定时任务和固定周期任务
SingleThreadExecutor:只有一个核心线程,无超时机制,保证只在一个线程中执行任务
线程池中一个线程崩溃会导致线程池崩溃吗?
不会,线程池存在两种方式去执行线程任务,submit和execute方式。 当发生线程崩溃时,execute下会将线程关闭,开辟新的线程,submit会返回异常,但不会关闭线程。
submit:
- 继承自ExecutorService
- 不会抛出栈堆异常,通过Future.get方法获取异常信息
- submit通过构造一个RunnableFuture后,执行execute方法,RunnableFuture内部使用状态管理,通过死循环判断任务执行状态,在执行完或者cancle后返回,
get()方法是一个阻塞方法,在调用时需要注意
execute:
- 继承自Executor
- 会抛出堆栈异常信息,关闭该线程并创建新的线程
如何检测线程池中的崩溃问题呢?
submit的get()方法可以获取崩溃,但是该方法是阻塞的,可用性不高,于是我们使用另一种方法
- execute+ThreadFactory.UncaughtExceptionHandler
在submit下UncaughtExceptionHandler失效,因为FutureTask会捕获异常并保存不会放入UncaughtExceptionHandler中 - 在run方法中自行捕获
- 重写ThreadLocalExecutor.afterExecute方法
- submit+get方法
View
触摸事件传递

DecorView为最顶层的view,DecorView、TitleView和ContentView都为FrameLayout
如果一个view处理了down事件,那么后续的move,up都会交给他处理
点击事件的传递流程
onTouchListener(onTouch)>onTouchEvent()>onClickListener(onClick)
onTouchListener的onTouch返回为false,则onTouchEvent被调用
简述view的事件传递
事件传递从父类向子类传递,其中包含3个方法,在一个类中顺序执行,
- dispatchEvent:事件的分发,true—->分发给自己
- onIntercepterEvent:事件拦截,true—->拦截后交给自己的onTouchEvent处理,false —->传递给子View
- onTouchEvent:事件的执行。

如果View没有对ACTION_DOWN进行消费,之后的事件也不会传递过来。
事件的传递是从Activity开始的,Activity –>PhoneWindow–>DectorView–>ViewGroup–>View;主要操作在ViewGroup和View中;
ViewGroup类主要调用:dispatchTouchEvent()–>onInterceptTouchEnent()–>dispatchTransformedTouchEvent();ViewGroup不直接调用onTouchEvent()方法;
| 类 | 相关子类 | 方法 |
|---|---|---|
| Activity类 | Activity…… | dispatchTouchEvent(); onTouchEvent(); |
| View容器(ViewGroup的子类) | FrameLayout、LinearLayout、ListView、ScrollVIew…… | dispatchTouchEvent(); onInterceptTouchEvent(); onTouchEvent(); |
| View控件(非ViewGroup子类) | Button、TextView、EditText…… | dispatchTouchEvent(); onTouchEvent(); |
onIntercepterTouchEvent()方法之只存在ViewGroup中,Activity为最顶层,不需要拦截,直接分发,view为最底层,不需要拦截,直接分发
- 以ACTION_DOWN为开始,UP或者CANCEL为结束
- 如果dispatch不处理ACTION_DOWN事件,那么就不会继续接收到后续的ACTION_xxxx事件
如何让只执行onTouch事件,不执行onClick事件?
将onTouch方法的返回值改为true,就会只执行onTouch事件,不执行onClick事件。
如果截取了事件,还会往下传吗?那会走到哪里?
如果截取了事件就不会往下传递了,只会执行本Viewgroup的onTouchEvent。
如果截取了事件并处理了事件还会返回父级吗?
会返回父类,因为父类需要确认子级是否已经处理了事件
requestDisallowInterceptTouchEvent
子view让其父view不做事件拦截,
在子view的onTouchEvent方法中调用parent.requestDisallowInterceptTouchEvent(true)方法,
如果父view拦截事件,是怎么通知到子view的onInterceptTouchEvent中调用disallowIntercepter?
在ScrollView中进行源码分析:
在onIntercepterTouchEvent中返回true,则进行拦截,在按下滑动一小部分距离后设置为false(ACTION_MOVE),可以进行事件传递,当然就可以调用disallowIntercepter方法进行处理,后续的值触发父view的机制,直接过滤掉了onIntercepterTouchEvent
所以在ScrollView中默认的onClickListener是不生效的
onIntercepterTouchEvent不执行,直接返回false,然后向下dispatch到子类
该方法生效的前提是父view不拦截ACTION_DOWN事件,第一次的ACTION_DOWN事件可以传递到子view中,则后续的ACTION事件父view无法拦截
如何解决滑动冲突
外部拦截法:
重写父view的onIntercepterTouchEvent,在其中对触摸的坐标进行控制,在父view要拦截的时候拦截,在子view想要调用的时候不进行拦截
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public boolean onInterceptTouchEvent(MotionEvent event) {
boolean intercepted = false;
int x = (int) event.getX();
int y = (int) event.getY();
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN: {
intercepted = false;
break;
}
case MotionEvent.ACTION_MOVE: {
if (满足父容器的拦截要求) {
intercepted = true;
} else {
intercepted = false;
}
break;
}
case MotionEvent.ACTION_UP: {
intercepted = false;
break;
}
default:
break;
}
mLastXIntercept = x;
mLastYIntercept = y;
return intercepted;
}
内部拦截法:
在子view的dispatchTouchEvent中在ACTION_DOWN事件下调用parent.requestDisallowInterceptTouchEvent(true);,设置不允许父view的拦截
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public boolean dispatchTouchEvent(MotionEvent event) {
int x = (int) event.getX();
int y = (int) event.getY();
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN: {
parent.requestDisallowInterceptTouchEvent(true);
break;
}
case MotionEvent.ACTION_MOVE: {
int deltaX = x - mLastX;
int deltaY = y - mLastY;
if (父容器需要此类点击事件) {
parent.requestDisallowInterceptTouchEvent(false);
}
break;
}
case MotionEvent.ACTION_UP: {
break;
}
default:
break;
}
mLastX = x;
mLastY = y;
return super.dispatchTouchEvent(event);
}该条件需要在父view的ACTION_DOWN事件可以传递到子view中才可以实现,所以需要在父view的onInterceptTouchEvent中不拦截父View的ACTION_DOWN事件
1
2
3
4
5
6
7
8
9public boolean onInterceptTouchEvent(MotionEvent event) {
int action = event.getAction();
if (action == MotionEvent.ACTION_DOWN) {
return false;
} else {
return true;
}
}
ACTION_CANCEL怎么理解?
- 在划出子view的布局后,onIntercepterTouchEvent进行拦截ACTION_MOVE事件,并将其转化为ACTION_CANCEL交给子view的处理,表示手指划出view所在区域
- 在父view进行拦截的时候,子view有可能接收到ACTION_CANCEL事件
触摸事件的结束有两种状态,一种时ACTION_UP事件,另一种就是ACTION_CANCEL事件,正常在view的事件传递中,抬起手指的ACTION_UP事件会被监听,当父view认为不需要将后续的ACTION_MOVE事件传递给子View的时候,就会将ACTION_MOVE事件转化为ACTION_CANCEL事件,子View就会认为事件结束
主要是父view在拦截中做了处理影响子view的触摸,不需要触摸就直接传ACTION_CANCEL。
使用TouchTarget(具体实现时mFirstTouchTarget)单链表存储触摸事件的,当置为CANCLE时,将触摸view在mFirstTouchEvent删除
事件到底是先到DecorView还是先到Window的?
ViewRootImpl——>DecorView——>Activity——>PhoneWindow——>DecorView——>ViewGroup
为什么绕来绕去的呢,光DecorView就走了两遍。
- ViewRootImpl并不知道有Activity这种东西存在,它只是持有了DecorView。所以先传给了DecorView,而DecorView知道有Activity,所以传给了Activity。
- Activity也不知道有DecorView,它只是持有PhoneWindow,所以这么一段调用链就形成了。
多点触控(非重点)
使用TouchTarge(mFirstTouchTarget)管理
1 | private static final class TouchTarget { |
- view:触摸目标view
- pointerIdBits:位运算(与、或)
- next:链表指针
第一个触摸目标,在ACTION_DOWN、ACTION_POINTER_DOWN时会触发寻找触摸目标过程(事件分发),所以DOWN事件会重置mFirstTouchTarget。
- 单点触控,mFirstTouchEvent为单个对象
- 多点触控,在一个view上,也是单个对象
- 多点触控,在多个view上,会成为一个链表
传入的view消耗了事件,则构建一个TouchTarget,并发至在mFirstTouchTarget的头部。多个view目标会头插在链表中。
即便是多指触控,也都是使用ACTION_MOVE,不做区分,可以使用index获取
如果ViewGroup是横向滑动的,RecyclerView是纵向滑动的,当调用RecyclerView进行纵向滑动时,在横向滑动会怎么样?
当使用纵向滑动,默认事件传递是viewPager到RecyclerView,即后续的所有事件都由RecyclerView进行处理,那么RecycleView没有横向事件,所以不会做处理,所以不会出现横向的滑动。
View的加载流程
简述View的加载流程
- 通过Activity的setContentView方法间接调用Phonewindow的setContentView(),在PhoneWindow中通过getLayoutInflate()得到LayoutInflate对象
- 通过LayoutInflate对象去加载View,主要步骤是
(1)通过xml的Pull方式去解析xml布局文件,获取xml信息,并保存缓存信息,因为这些数据是静态不变的
(2)根据xml的tag标签通过反射创建View逐层构建View
(3)递归构建其中的子View,并将子View添加到父ViewGroup中
加载结束后就开始绘制view了
View的绘制机制
DecorView为最顶层的view,DecorView、TitleView和ContentView都为FrameLayout,
当Activity对象被创建完毕后,会将DecorView添加到PhoneWindow中,同时会创建ViewRootImpl对象,并将ViewRootImpl对象和DecorView建立关联,view的绘制过程是由ViewRootImpl完成的。
所有的view都是依附在window上的,比如PopupWindow、菜单。
Window是个概念性的东西,你看不到他,如果你能感知它的存在,那么就是通过View,所以View是Window的存在形式,有了View,你才感知到View外层有一个皇帝的新衣——window
有视图的地方就有window
简述View的绘制流程
深度便利
主要分为3个方法,顺序执行:
- measure():测量视图的大小,根据MeasureSpec进行计算大小
- layout():确定view的位置
- draw():绘制view。创建Canvas对象。六个步骤:①、绘制视图的背景;②、保存画布的图层(Layer);③、绘制View的内容;④、绘制View子视图,如果没有就不用;⑤、还原图层(Layer);⑥、绘制滚动条。
draw()中的具体流程是什么?
- 绘制背景:drawBackground(canvas)
- 绘制自己的内容:onDraw(canvas)
- 绘制Children:dispatchDraw(canvas)
- 绘制装饰:onDrawForeground(canvas)
MeasureSpec分析
MeasureSpec是由父View的MeasureSpec和子View的LayoutParams通过简单的计算得出一个针对子View的测量要求,子view依据该值进行大小的绘制
MeasureSpec是个大小和模式的组合值。是一个32位的整型,将size(大小)和mode(模式)打包成一个int,其中高两位是mode,其余30位存储size(大小)1
2
3
4
5
6
7
8// 获取测量模式
int specMode = MeasureSpec.getMode(measureSpec)
// 获取测量大小
int specSize = MeasureSpec.getSize(measureSpec)
// 通过Mode 和 Size 生成新的SpecMode
int measureSpec=MeasureSpec.makeMeasureSpec(size, mode);
测量模式有三种:
- EXACTLY: 相等于MATCH_CONTENT
- AT_MOST: 相等于WRAP_CONTENT
- UNSPECIFIED: 相等于具体的值
RelativeLayout、LinearLayout和ConstraintLayout
LinearLayout:
- weight设置导致二次测量,首先测量一遍大小onMeasure(非weight),然后根据weight在次测量,调整大小
RelativeLayout:
- onMeasure执行两遍,对横向和纵向分别测量,所以是2遍
ConstraintLayout:
- 可以不使用嵌套,提供相对布局,并且支持权重布局,尽可能减少层级,提高性能,类似于flex布局
对比
- 同层级的布局,LinearLayout<RelatvieLayout=ConstraintLayout,因为LinearLayout执行onMeasure一遍,RelativeLayout执行两遍
- LinearLayout会增加层级深度,RelativeLayout减少层级,所以通常下使用RelativeLayout,如果层级简单则使用LinearLayout
RelativeLayout的子View如果高度和RelativeLayout不同,会引发效率问题
setContentView的执行过程
- 初始化windows
- 绑定ui布局
什么时候可以获得view的宽高
因为onMeasure和生命周期不同步,所以不能在onCreate,onStart,onResume中进行获取操作,
- 在view.post方法中进行获取,内部实现是handler机制,回调的时候已经执行完了
- 在onWindowFocusChanged获取焦点后,view的绘制完成,可以在这里拿到view的宽高
- 使用ViewTreeObserver的回调也可以解决这个问题。
1
2
3
4
5
6
7
8
9
10
11
12
13ViewTreeObserver observer = tv1.getViewTreeObserver();
observer.addOnGlobalLayoutListener(new ViewTreeObserver.OnGlobalLayoutListener() {
public void onGlobalLayout() {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.JELLY_BEAN) {
tv1.getViewTreeObserver().removeOnGlobalLayoutListener(this);
}
int width = tv1.getMeasuredWidth();
int height = tv1.getMeasuredHeight();
Log.d("tv1Width", String.valueOf(width));
Log.d("tv1Height", String.valueOf(height));
}
}); - 手动调用measure方法后,获取宽高
什么时候开始绘制Activity的view的?
在DecorView添加(addView)到phoneWindows中时,触发measure,layout,draw方法
PhoneWindow是在什么时候创建的?
在Activity的attch方法时,创建了PhoneWindow
View的刷新机制
requestLayout和invalidate区别是什么
requestLayout:触发onMeasure,onLayout方法,大小和位置变化,不一定触发onDraw
invalidate:触发performTraversals机制,导致view重绘,调用onDraw方法,主要是内容发生变化
postInvalidate:异步调用invalidate方法
invalidate如果是个view,那就只有自己本身会draw,如果是ViewGroup就是对子view进行重绘
简析Activity、Window、DecorView以及ViewRoot之间的错综关系
Activity是控制器
windows装载DecorView,并将DecorView交给ViewRoot进行绘制和交互,其唯一实现子类就是PhoneWindow,在attach中创建,是Activity和View交互的中间层,帮助Activity管理View。
- DecorView是FrameLayout的子类,是视图的顶级view
- viewRoot负责view的绘制和交互,实际的viewRoot就是ViewRootImpl类,是连接WMS和DecorView的纽带
setContentView执行的具体过程
- Activity实例化,执行attach方法,在attach中创建PhoneWindow
- 执行onCreate方法,执行setContentView,先调用phoneWindow.setContentView(),然后开始根据不同的主题创建DecorView的结构,传入我们的xml文件,生成一个多结构的View
- Activity调用onResume方法,调用WindowManager.addView()方法,随后在addView()方法中创建ViewRootImpl
- 接着调用ViewRootImpl的setView方法,最终触发meaure,layout,draw方法进行渲染绘制,其中和WMS通过Binder交互,最终显示在界面上
四者的创建时机?
- Activity:startActivity后,performLaunchActivity方法中创建
- PhoneWindow:Activity的attach方法
- DecorView:setConentView中创建
- ViewRootImpl:onResume中调用WM.addView方法创建
dialog为什么不能用application创建?
Android-Window机制原理之Token验证(为什么Application的Context不能show dialog)
token是WMS唯一用来标识系统中的一个窗口
Dialog有一个PhoneWindow实例,属于应用窗口。Dialog最终也是通过系统的WindowManager把自己的Window添加到WMS上。Dialog是一个子Window,需要依附一个父window。
Dialog创建PhoneWindow时,token是null。只有传入Activity中的Context对象,Activity才会将自己的token给Dialog,这样,才会被WMS所识别,如果使用的不是Activit的token,就会报错BadTokenException
在application的情况下,将Dialog的window升级为系统window即可显示
RecyclerView和ListView
Android—RecyclerView进阶(4)—复用机制及性能优化
简述RecyclerView的刷新和缓存机制
recyclerView中有三个重要方:
- Adapter:负责与数据集交互
- LayoutManager:负责ItemView的布局,接管Measure,Layout,Draw过程
- Recycler:负责管理ViewHolder
- ViewHolder:视图的创建和显示在Recycler中有多个缓存池,
mAttachedScrap被称为一级缓存,在重新layout时使用,主要是数据集发生变化的场景
1 | //屏幕内缓存scrap |
- mAttachedScrap:mAttachedScrap用于屏幕中可见表项的回收和复用,没有大小限制
mAttachedScrap生命周期起始于RecyclerView布局开始,终止于RecyclerView布局结束,无论mAttachedScrap中是否存在数据,都会清空,存储到mCacheView或者mRecyclerPool
插入或是删除itemView时,先把屏幕内的ViewHolder保存至AttachedScrap中
mAttachView和mCacheView都是通过比对position或者id(setStableIds(true)+getItemId复写)来确定是否复用的
缓存存储结构区别
- mAttachedScrap:ArrayList
- mCachedView:ArrayList
- mRecyclerPool:SparseArray
,ScrapData中包含ArrayList 和其他标记位。 数据集发生变化
当数据集发生变化后,我们会调用notifyDataSetChanged()方法进行刷新布局操作,这时LayouManager通过调用detachAndScrapAttachedViews方法,将布局中正在显示的ItemView缓存到mAttachScrap中,重新构建ItemView时,LayoutManager会首先到mAttachScrap中进行查找
如图所示,如果只是删除Data1数据,执行NotifyDataSetChanged()方法时,layoutManager将Data0到Data4缓存到mAttachScrap中,重新渲染布局时,会直接复用mAttachScrap中的四个布局,而得不到复用的布局会被放置在mRecyclerPool中。
通过比较Position确定mAttachScrap中ItemView的复用,因为2的位置从2变为1,位置发生变化,但是还是通过比对position进行复用,那是因为在recyclerView重新渲染时,执行dispatchLayoutStep1()对position进行了校正。
滑动类型
在滑出可视区域后,会将ViewHolder存储在mCachedView中,当超出大小(默认大小为2+预加载item)后会将最先放进来的放在RecyclerViewPool中,根据viewType进行缓存,每个viewType缓存最多5个,从RecyclerViewPool中取出的数据,最终会调用onBindViewHolder()方法重新绑定
当发现有新的构建时,会去缓存找,找不到就去mRecyclerPool中寻找,如果有viewType相同的就取出来绑定并复用。
RecyclerView滑动时,刚开始的时候回收了Position0和Position1,它们被添加到了mCachedViews中。随后回收Position2时,达到数量上限,最先进入mCachedViews的Position0被放进了mRecyclerPool中。
再看下方进入可视区域的3个Item,最初的Position6和Position7找不到对应的缓存,只能新建ViewHolder并绑定。当Position8滑入可视区域时,发现mRecyclerPool中有一个ViewType相等的缓存,则将其取出并绑定数据进行复用。
当有数据进行变动时,数据的position会发生变化。
stableId
mChangedScrap—–>mAttachedScrap—–>mCachedViews—–>ViewCacheExtension—–>RecycledViewPool——–>onCreatViewHolder
如果是单个viewType的RecyclerView,在滑动过程中,RecyclerPool最多可能存在一个数据
假设一屏幕显示7个,向上滑动10个,总共bindView10个,又下滑10个(滑回去),总共8个(cacheView复用两个),一共18个
在RecyclerView的v25版本中,引入预取机制,在初始化时,初始化8个,提前缓存一个数据
RecyclerView的优化
放大缓存大小和缓存池大小
- 再滑动过程中,不论上滑还是下滑都会从mCachedViews中查找缓存,如果滑动频繁,可以通过
RecyclerView.setItemViewCacheSize(...)方法增大mCachedViews的大小,减少onBindViewHolder()和onCreateViewHolder()调用 - 放大RecyclerViewPool的默认大小,现在是每个viewType中默认大小为5,如果显示数据过多,可放大默认大小如果多个RecyclerView中存在相同ViewType的ItemView,那么这些RecyclerView可以公用一个mRecyclerPool。
1
2//设置viewType类型的默认存储大小为10
recyclerview.getRecycledViewPool().setMaxRecycledViews(viewType,10);
优化onBindViewHolder()耗时
尽量少的在onBindViewHolder中执行操作,减少新建对象对内消耗
布局优化
多使用include,merage,viewStub,LinearLayout,FrameLayout
measure()优化和减少requestLayout()调用
当RecyclerView宽高的测量模式都是EXACTLY(精确数据)时,onMeasure()方法不需要执行dispatchLayoutStep1()等方法来进行测量。而当RecyclerView的宽高不确定并且至少一个child的宽高不确定时,要measure两遍。
因此将RecyclerView的宽高模式都设置为EXACTLY有助于优化性能。
如果RecyclerView的宽高都不会变,大小不变,方法RecyclerView.setHasFixedSize(true)可以避免数据改变时重新计算RecyclerView的大小,优化性能
notifyDataSetChanged 与 notifyItemRangeChanged 的区别?
当notifyItemRangeChanged的区间在mRecyclerpool的大小的间隔内,则会通过mRecyclerpool复用viewholder,响应快速。
notifyItemInsert()和notifyItemRemove()方法,会通过RecyclerView的预加载流程,会将ViewHolder缓存到mAttachView中,避免重新create和bind。
notifyItemChanged(int)方法更新固定item
notifyDataSetChanged 会将所有viewholder放置在pool中,但是只能放置5个,其他就回收了,再构建时,需要重新绘制测量,界面会导致闪烁等
如果使用SetHasStableIds(true),会将数据缓存到scrap中,复用时直接使用
调用 notifyDataSetChanged 时闪烁的原因?
itemView重新测量和布局导致的(bindViewHolder),并非createViewHolder。数据存储在RecyclerViewPool中,拿出需要重新BindView,itemView重新进行测量和布局,导致出现UI线程耗时,出现闪烁
如果使用SetHasStableIds(true),会将数据缓存到scrap中,复用时直接使用
如果你的列表能够容纳很多行,而且使用 notifyDataSetChanged 方法比较频繁,那么你应该考虑设置一下容量大小。
RecyclerView相对于ListView的优势是什么?
- 屏幕外缓存可以直接在mCacheView()中复用,不需要重新BindView
- recyclerPool可以提供给多个RecyclerView使用,在特定场景下,如viewpaper+多个列表页下有优势.
- ListView缓存View,RecyclerView缓存ViewHolder
adapter,viewHolder的作用?adapter中常用方法的作用是什么?
- Adapter:负责与数据集交互
- ViewHolder:视图的创建和显示,持有所有的用于绑定数据或者需要操作的View
1 | //创建Item视图,并返回相应的ViewHolder |
RecyclerPool为何使用SparseArray?
在RecyclerView中,第四级缓存,mRecyclerPool中存储是通过SparseArray存储ViewHolder,根据不同的ViewType的int值为键,ScrapData为值,ScrapData也是ArrayList
不使用HashMap的原因是:
- 我们定义了viewType为int值,则不用HashMap中较为繁重的类型,减少装箱问题耗时
- 量级较小,不需要HashMap的大量级处理
- 节省内存
使用SparseArray存储空间id和空间对象关系。
HashMap更加复杂,SparseArray减少开销
LayoutManager样式有哪些?setLayoutManager源码里做了什么?
- LinearLayoutManager 水平或者垂直的Item视图。
- GridLayoutManager 网格Item视图。
- StaggeredGridLayoutManager 交错的网格Item视图。
当之前设置过 LayoutManager 时,移除之前的视图,并缓存视图在 Recycler 中,将新的 mLayout 对象与 RecyclerView 绑定,更新缓存 View 的数量。最后去调用 requestLayout ,重新请求 measure、layout、draw。
ItemDecoration的用途是什么?自定义ItemDecoration有哪些重写方法?分析一下addItemDecoration()源码?
用途:来改变Item之间的偏移量或者对Item进行装饰
1 | //装饰的绘制在Item条目绘制之前调用,所以这有可能被Item的内容所遮挡 |
当通过这个方法添加分割线后,会指定添加分割线在集合中的索引,然后再重新请求 View 的测量、布局、(绘制)
mChangedScrap和mAttachedScrap的区别是什么?
因为mChangedScrap表示item变化了,有可能是数据变化,有可能是类型变化,所以它的viewHolder无法重用,只能去RecycledViewPool中重新取对应的,然后再重新绑定。
mChangedScrap与mAttachedScrap,作用差不多。
mChangedScrap更多的用于pre-layout的动画处理。
然后一点需要注意:mChangedScrap只能在pre-layout中使用,mAttachedScrap可以在pre-layout与post-layout中使用。
mChangedScrap:ViewHolder.isUpdated() == true
mAttachedScrap:1.被同时标记为remove和invalid;2.完全没有改变的ViewHolder
在notifyItemRangeChanged,将数据变化的放置在mChangedScrap,没有变化的存储在mAttachScrap中,然后再取出来,mChangedScrap的数据会被移动到RecyclerPool中,进行重新绑定后再放回mChangedScrap中
mAttachScrap中得不到复用的会放置在recyclerpool中
onMeasure过程
过程中包含mAttachedScrap的使用
dispatchLayoutStep1:预布局
dispatchLayoutStep2:实际布局
dispatchLayoutStep3:执行动画信息
如何解决Glide错乱问题
因为存在复用机制,8可能会复用1,在网络不好或者图片过大的情况下,8的图片加载缓慢,会先显示1的图片,加载后才会刷新掉。
方案:imageView设置tag,判断是否复用,如果是复用,就清除该控件上Glide的缓存
RecyclerView卡顿优化
通过BlockCanary进行主线程卡顿检测,打印出任务耗时,在卡顿时,打印出栈堆信息
原理是在looper.loop()死循环中,执行任务都是dispatchMessage方法,如果该方法超过一个任务的常规耗时,就会导致主线程卡顿
解决方法:
放大mCacheView和RecyclerPool的大小,提高复用率,减少渲染
图片在滑动结束后再进行加载,避免在滑动的时候向主线程做更新
1
2
3
4
5
6
7
8
9
10mRecyclerView.addOnScrollListener(new RecyclerView.OnScrollListener() {
public void onScrollStateChanged(RecyclerView recyclerView, int newState) {
if (newState == RecyclerView.SCROLL_STATE_IDLE) {
Glide.with(mContext).resumeRequests();
}else {
Glide.with(mContext).pauseRequests();
}
}
});在滑动过程中停止加载,在滑动结束后恢复加载
使用DiffUtil进行局部刷新优化
1
2
3
4
5
6//DiffUtil会自动计算新老数据的差异,自动调用notifyxxx方法,将无脑的notifyDataSetChanged()进行优化
//并且伴随动画
adapter.notifyItemRangeInserted(position, count);
adapter.notifyItemRangeRemoved(position, count);
adapter.notifyItemMoved(fromPosition, toPosition);
adapter.notifyItemRangeChanged(position, count, payload);1
2
3
4
5
6
7
8//文艺青年新宠
//利用DiffUtil.calculateDiff()方法,传入一个规则DiffUtil.Callback对象,和是否检测移动item的 boolean变量,得到DiffUtil.DiffResult 的对象
DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(new DiffCallBack(mDatas, newDatas), true);
//利用DiffUtil.DiffResult对象的dispatchUpdatesTo()方法,传入RecyclerView的Adapter,轻松成为文艺青年
diffResult.dispatchUpdatesTo(mAdapter);
//别忘了将新数据给Adapter
mDatas = newDatas;
mAdapter.setDatas(mDatas);
减少布局的嵌套和层级,减少过度绘制,尽量自定义view
如果Item高度固定,调用
RecyclerView.setHasFixedSize(true);来避免requestLayout浪费资源可以关闭动画,减少RecyclerView的渲染次数
RecyclerView的自适应高度
- 使用瀑布流布局StaggeredGridLayoutManager
- 重写LinearLayoutManager,onMeasure中重新测量子布局的大小
RecyclerView嵌套RecyclerView滑动冲突,NestedScrollView嵌套RecyclerView
- 同方向的情况下会造成滑动冲突,默认外层的RecyclerView可滑动
一般有两种处理方案:内部拦截法和外部拦截法
这里推荐内部拦截法,通过设置requestDisallowInterceptTouchEvent(true)时,不让父RecyclerView拦截子类的事件 - ScrollView嵌套RecyclerView同样可以使用这个方法解决。也可以使用NestedScrollView,该类就是为了解决滑动冲突问题,可以保证两View类都可以滑动,但是需要设置RecyclerView.setNestedScrollingEnabled(false),取消RecyclerView本身的滑动效果。解决滑动的卡顿感
动画
简述
帧动画:一连串的图片进行连贯的播放,形成动画。
补间动画:通过xml文件实现,实现 alpha(淡入淡出),translate(位移),scale(缩放大小),rotate(旋转),通过不断的绘制view,看起来移动了效果,实际上view没有变化,还在原地
属性动画:对于对象属性的动画,也可以使用xml配置,但是推荐代码配置,比xml更加方便。通过不断改变自己view的属性值,真正的改变view
所有的补间动画都可以用属性动画实现
属性动画和补间动画的区别
- 补间动画虽然移动了,但是点击的还是原来的位置,点击事件允许触发。而属性动画不是,所以我们可以确认,属性动画才是真正实现了View的移动,补间动画的view其实只是在其他地方绘制了一个影子
- Activity退出时,没有关闭动画,属性动画会导致Activity无法释放的内存泄漏,而补间动画不会发生这样的情况
- xml的补间动画复用率极高,在页面切换过程中都有很好的效果
帧动画避免大图,否则会带来oom
属性动画中的差值器和估值器是什么?
差值器:定义动画随时间流逝的变化规律。通俗点就是动画的执行速度的变化,可以是由缓即快,由快即缓,也可以是匀速,也可以是弹性动画效果 ,LinearInterpolator(匀速差值器)
估值器:定义从初始值过渡到结束值的规则定义,TypeEvaluator,可以通俗的理解为位置的移动
android系统启动流程
android系统架构
简述系统启动流程
从系统层看:
- linux 系统层
- Android系统服务层
- Zygote
从开机启动到Home Launcher:
- 启动bootloader (小程序;初始化硬件)
- 加载系统内核 (先进入实模式代码在进入保护模式代码)
- 启动init进程(用户级进程 ,进程号为1)
- 启动Zygote进程(初始化Dalvik VM等)
- 启动Runtime进程
- 启动本地服务(system service)
- 启动 HomeLauncher
第一个启动的进程是什么?
init进程,其他进程都是fork这个进程的
init进程孵化出了什么进程?
- 守护进程
- Zygote进程,负责孵化应用进程
- MediaServer进程
Zygote进程做了什么?
- 创建Socket服务端
- 加载虚拟机
- SystemServer进程
- fork第一个应用进程—Launcher
为什么要创建Socket服务端?
- ServiceManager不能保证在孵化Zygote进程时就初始化好了,所以无法使用Binder
- Binder属于多线程操作,fork不允许多线程操作,容易发生死锁,所以使用Socket
app启动流程
- 用户点击 icon
- 系统开始加载和启动应用
- 应用启动:开启空白(黑色)窗口
- 创建应用进程
- 初始化Application
- 启动 UI 线程
- 创建第一个 Activity
- 解析(Inflater)和加载内容视图
- 布局(Layout)
- 绘制(Draw)
源码分析
- LauncherActivity.startActivitySafely(intent):使用intent启动
- Activity.startActivity(intent):
- Activity.startActivityForResult(intent):获取ApplicationThread成员变量,是一个Binder对象
- Instrumentation.execStartActivity:ActivityManagerService的远程接口
- ActivityManagerProxy.startActivity:通过Binder进入AMS
- ActivityManagerService.startActivity
- ActivityStack.startActivityMayWait:解析MainActivity的信息
- ActivityStack.startActivityLocked:创建即将要启动的Activity的相关信息
- ActivityStack.startActivityUncheckedLocked:获取intent标志位,新建Task栈,添加到AMS中
- Activity.resumeTopActivityLocked:查看LauncherActivity状态,新建Activity的状态
- ActivityStack.startPausingLocked:停止LauncherActivity,onPause
- ApplicationThreadProxy.schedulePauseActivity
- ApplicationThread.schedulePauseActivity
- ActivityThread.queueOrSendMessage:在主线程通过Handler发送消息
- H.handleMessage:Handler的回调
- ActivityThread.handlePauseActivity:pause LauncherActivity
- ActivityManagerProxy.activityPaused:进入AMS中的onPause事件
- ActivityManagerService.activityPaused
- ActivityStack.activityPaused
- ActivityStack.completePauseLocked
- ActivityStack.resumeTopActivityLokced:LauncherActivity已经onPause了
- ActivityStack.startSpecificActivityLocked
- ActivityManagerService.startProcessLocked:创建新进程
- ActivityThread.main:app入口,添加looper循环
- ActivityManagerProxy.attachApplication:通过Binder进入AMS中
- ActivityManagerService.attachApplication
- ActivityManagerService.attachApplicationLocked
- ActivityStack.realStartActivityLocked
- ApplicationThreadProxy.scheduleLaunchActivity:进入ApplicationThread
- ApplicationThread.scheduleLaunchActivity
- ActivityThread.queueOrSendMessage
- H.handleMessage
- ActivityThread.handleLaunchActivity
- ActivityThread.performLaunchActivity:进入onCreat方法
- MainActivity.onCreate
总结:
1~11:Launcher通过Binder进程通知ActivityManagerService,他要启动一个Activity
12~16:ActivityManagerService通过Binder进程通知Launcher进入Pause阶段
17~24:Launcher告知我已进入pause阶段,ActivityManagerService创建新进程,用来启动ActivityThread。
25~27:ActivityThread通过Binder进程将ApplicationThread的Binder传递给ActivityManagerService,以便AMS可以直接用这个Binder通信
28~35:AMS通过Binder通知ActivityThread,你可以启动
这里以启动微信为例子说明
- Launcher通知AMS 要启动微信了,并且告诉AMS要启动的是哪个页面也就是首页是哪个页面
- AMS收到消息告诉Launcher知道了,并且把要启动的页面记下来
- Launcher进入Paused状态,告诉AMS,你去找微信吧
上述就是Launcher和AMS的交互过程
- AMS检查微信是否已经启动了也就是是否在后台运行,如果是在后台运行就直接启动,如果不是,AMS会在新的进程中创建一个ActivityThread对象,并启动其中的main函数。
- 微信启动后告诉AMS,启动好了
- AMS通过之前的记录找出微信的首页,告诉微信应该启动哪个页面
- 微信按照AMS通知的页面去启动就启动成功了。
Activity启动流程
参照app的启动流程
- ApplicationThread:ActivityThread的内部类,负责和AMS进行Binder通信
- ActivityManagerService:服务端对象,负责管理系统中所有的Activity
Activity 启动过程是由 ActivityMangerService(AMS) 来启动的,底层 原理是 Binder实现的 最终交给 ActivityThread 的 performActivity 方法来启动她
ActivityThread大概可以分为以下五个步骤
- 通过ActivityClientRecord对象获取Activity的组件信息
- 通过Instrument的newActivity使用类加载器创建Activity对象
- 检验Application是否存在,不存在的话,创建一个,保证 只有一个Application
- 通过ContextImpl和Activity的attach方法来完成一些初始化操作
- 调用oncreat方法
Android开启新进程的方式是通过复制第一个zygote(受精卵)进程实现,所以像受精卵一样快速分裂
SystemServer是什么?有什么作用?他和zygote的关系是什么?
SystemServer也是一个进程,并且复制于zygote,系统中重要的服务都是在这个进程中开启的,如:AMS,PMS,WMS等
ActivityManagerService是什么?什么时候初始化的?有什么作用?
简称AMS,负责系统中所有Activity的生命周期,控制其开启、关闭、暂停等
是在SystemServer进程开启时进行初始化的
App 和 AMS(SystemServer 进程)还有 zygote 进程是如何通信的?
App 与 AMS 通过 Binder 进行 IPC 通信,AMS(SystemServer 进程)与 zygote 通过 Socket 进行 IPC 通信。
AMS/PMS/WMS运行在一个线程中还是进程中?
运行在System_server进程中的线程中
apk打包流程
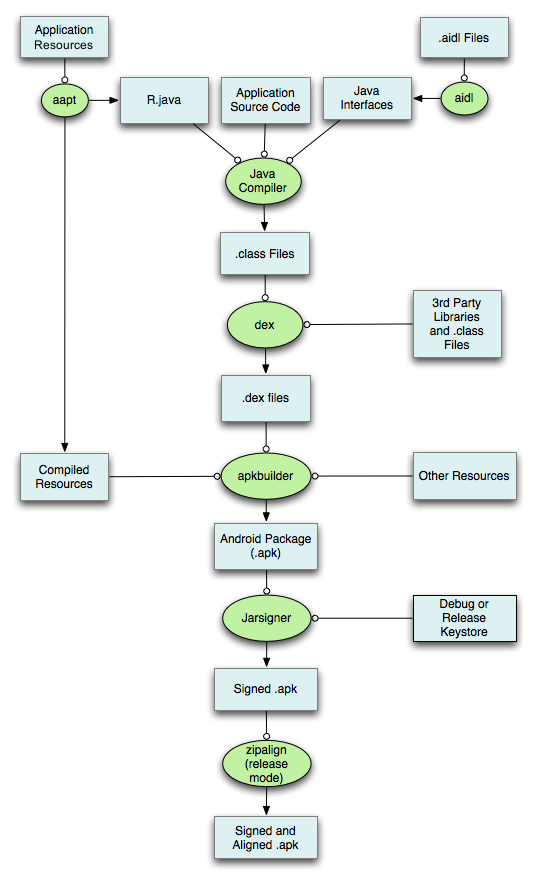
- aapt阶段,打包res目录,生成R.java
- AIDL阶段,生成java文件
- java编译器。将java文件通过javac编译生成
.class文件 - dex阶段,生成
.dex文件 - apk打包阶段,将文件打包成为apk文件
- 签名阶段,对apk进行签名
- 整理apk文件
aapt和aapt2的区别?
aapt是全量编译,打包res目录,生成R文件
aapt2是差量编译,将变化的res目录进行重新打包,修改R文件
aapt2中存在两部分,编译和链接
编译:将资源文件编译为二进制文件
链接:将编译后二进制文件进行合并,生成独立的文件
在需要差量的时候,只需要重新编译二进制文件,再将这些二进制文件生成新的文件即可
apk的组成
- AndroidManifest.xml
- assets(项目中assets目录)
- classes.dex
- lib库
- META-INF(校验文件)
- res(资源文件)
- resources.arsc(资源文件映射,索引文件)
apk安装流程
存在多少种安装方式,分别是什么?
四种
- 系统应用安装——————开机时完成安装,没有安装界面
- 网络下载安装——————通过市场应用完成,没有安装界面
- adb命令安装——————没有安装界面
- 第三方应用安装——————sdk卡导入apk,点击安装,存在安装界面
安装过程中的重要路径
应用安装涉及到如下几个目录:
system/app —————系统自带的应用程序,获得adb root权限才能删除
data/app —————用户程序安装的目录。安装时把 apk文件复制到此目录
data/data —————存放应用程序的数据
data/dalvik-cache——–将apk中的dex文件安装到dalvik-cache目录下(dex文件是dalvik虚拟机的可执行文件,其大小约为原始apk文件大小的四分之一)
安装过程
- 将apk文件复制到/data/app目录
- 解析apk信息
- dexopt操作(将dex文件优化为odex文件)
- 更新权限信息
- 发送安装完成广播
Android虚拟机发展史
- android初期,Dalvik负责加载dex/odex文件
- 2.2版本,JIT(即时编译)初次加入,每次启动的时候编译,耗时,耗电
- 4.4版本引入ART(Android RunTime)和AOT(Ahead-of-time)(运行前编译成机器码),与Dalvik共存
- 5.0版本全部采用ART编译器,不耗时,不耗电,在安装期间比较慢而已,而且会占用额外的控件存储机器码
- 7.0版本JIT回归,再用JIT/AOT并用,即初次启动使用JIT,在手机空闲时,使用AOT生成机器码(只编译热点函数信息,用户操作次数越多,性能越高),这样保证了安装迅速,启动迅速,耗电少
Dalvik和ART是什么,有啥区别?
Dalvik
Dalvik是Google公司自己设计用于Android平台的虚拟机。支持已转换为.dex格式的Java应用程序的运行,.dex格式是专为Dalvik设计的一种压缩格式,适合内存和处理器速度有限的系统。
Dalvik 经过优化,允许在有限的内存中同时运行多个虚拟机的实例,并且每一个Dalvik 应用作为一个独立的Linux 进程执行。独立的进程可以防止在虚拟机崩溃的时候所有程序都被关闭。
很长时间以来,Dalvik虚拟机一直被用户指责为拖慢安卓系统运行速度不如IOS的根源。
2014年6月25日,Android L 正式亮相于召开的谷歌I/O大会,Android L 改动幅度较大,谷歌将直接删除Dalvik,代替它的是传闻已久的ART。
ART
即Android Runtime
ART 的机制与 Dalvik 不同。在Dalvik下,应用每次运行的时候,字节码都需要通过即时编译器(just in time ,JIT)转换为机器码,这会拖慢应用的运行效率,而在ART 环境中,应用在第一次安装的时候,字节码就会预先编译成机器码,使其成为真正的本地应用。这个过程叫做预编译(AOT,Ahead-Of-Time)。这样的话,应用的启动(首次)和执行都会变得更加快速。
区别
Dalvik是基于寄存器的,而JVM是基于栈的。
Dalvik运行dex文件,而JVM运行java字节码
自Android 2.2开始,Dalvik支持JIT(just-in-time,即时编译技术)。
优化后的Dalvik较其他标准虚拟机存在一些不同特性:
1.占用更少空间
2.为简化翻译,常量池只使用32位索引
3.标准Java字节码实行8位堆栈指令,Dalvik使用16位指令集直接作用于局部变量。局部变量通常来自4位的“虚拟寄存器”区。这样减少了Dalvik的指令计数,提高了翻译速度。
当Android启动时,Dalvik VM 监视所有的程序(APK),并且创建依存关系树,为每个程序优化代码并存储在Dalvik缓存中。Dalvik第一次加载后会生成Cache文件,以提供下次快速加载,所以第一次会很慢。
Dalvik解释器采用预先算好的Goto地址,每个指令对内存的访问都在64字节边界上对齐。这样可以节省一个指令后进行查表的时间。为了强化功能, Dalvik还提供了快速翻译器(Fast Interpreter)。
对比
ART有什么优缺点呢?
优点:
1、系统性能的显著提升。
2、应用启动更快、运行更快、体验更流畅、触感反馈更及时。
3、更长的电池续航能力。
4、支持更低的硬件。
缺点:
1.机器码占用的存储空间更大,字节码变为机器码之后,可能会增加10%-20%
2.应用的安装时间会变长
.dex .class .odex的区别
.dex是谷歌对.class文件进行了优化后得到的文件格式
- .dex去除了.class中冗余的信息,更加轻量
- .class内存占用大,不适合移动端,堆栈的加栈模式,加载速度慢,文件IO操作多,类查找慢
.dex文件在虚拟机进行加载时,会预加载成.odex文件,.odex文件对.dex文件进行了优化,避免了重复验证和优化处理,启动时,可直接接在odex文件,提升app启动的速度
简述安装流程
- 使用installPackageAsUser判断安装来源
- 校验后(权限,存储空间,安全)将apk文件copy至data/app目录
- 解析apk信息,覆盖安装或者安装新应用
Dalvik中将dex优化为odex文件
ART将dex翻译为oat文件(机器码)预编译过程创建/data/data/包名 存放应用数据,发送广播结束安装
接口加密
项目中的接口加密技巧
在版本中写死一个密钥,首个接口请求后返回该app的密钥。
对上传的get,post请求的参数以ASCII码进行排序+密钥后生成md5值,添加到header中,传递给服务器
服务器端根据获取到的参数依据同样的规则生成md5后进行比较,如果相同,比较时间戳是否在5秒内,通过则成功
不使用token机制的原因是本产品不存在账号密码等机制,应用可能一直保持在线状态,不会下线,需要协调token的时效性,所以不使用该方案。
缺点:token机制一台机子只允许一个token进行访问,而上述方案没有该限制
常规token校验机制
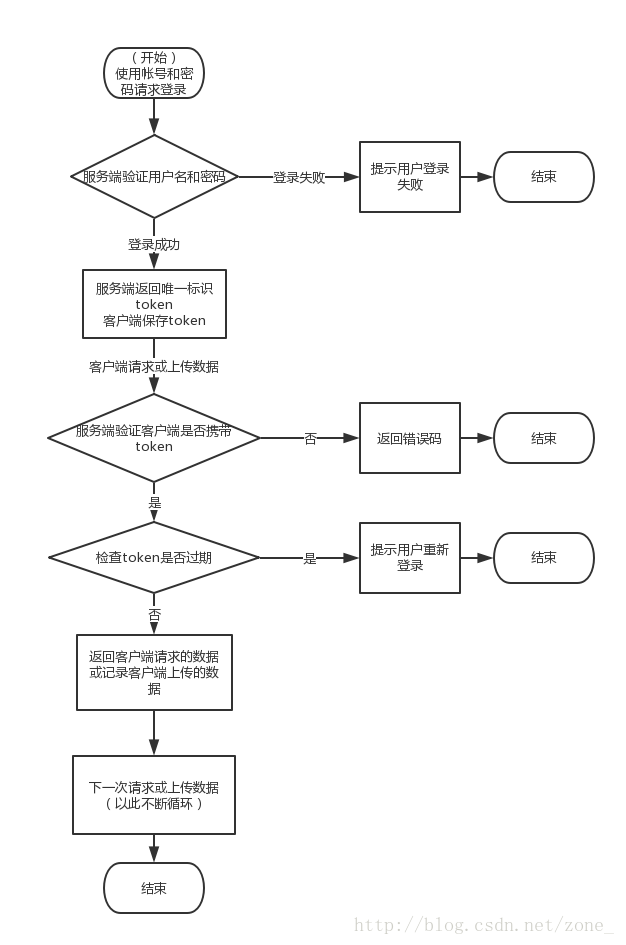
适用于存在账户名密码的应用
小知识点
ANR条件?
Service执行的操作最多是20s,BroadcastReceiver是10s,Activity是5s,超过时间发生ANR
ANR原理解析
Application Not Responding
- 主线程频繁进行IO操作,比如读写文件或者数据库;
- 硬件操作如进行调用照相机或者录音等操作;
- 多线程操作的死锁,导致主线程等待超时;
- 主线程操作调用join()方法、sleep()方法或者wait()方法;
- 耗时动画/耗资源行为导致CPU负载过重
- system server中发生WatchDog ANR;
- service binder的数量达到上限
在应用程序运行过程中,通过send一个延迟的handler,延迟时间为设置的anr时间,如果到时间,没有执行完任务/没有移除handler任务,就会调用appNotResponding方法,触发anr
主要在AMS和WMS中进行控制,通过获取/data/anr/trace.txt进行分析
什么情况下会导致oom?
- 大图片存储导致oom,内存溢出
- 使用软弱引用,当内存不足时,删除Bitmap缓存
- 调用Bitmap.recycle()快速回收,但是慎用,容易报错
- 除了程序计数器之外的内存模型都会发生oom
1
java.lang.StackOverflowError:死循环/递归调用产生的
- 关闭流文件、数据库cursor等对象关闭
- 创建很多线程会导致oom,因为开辟线程需要对虚拟机栈,本地方法栈,程序计数器,开辟内存,线程数量过多,会导致OOM
如何将应用设置为Launcher?
设置HOME,DEFAULT。
MVC,MVP,MVVM
MVC
- View:对应于布局文件
- Model:业务逻辑和实体模型
- Controller:对应于Activity
缺点:
- Controller(Activity)中处理的逻辑过于繁重,原因是在Activity有太多操作View的代码,View和Controller绑定太过紧密
android中算不上mvc模式,Activity可以叫View层,也可以叫Controller层,所有代码基本都在Activity中
MVP
- View 对应于Activity,负责View的绘制以及与用户交互
- Model 依然是业务逻辑和实体模型
- Presenter 负责完成View于Model间的交互
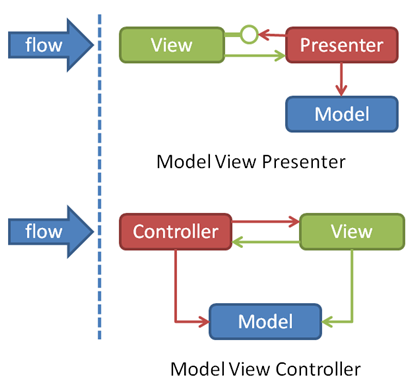
因为Activity任务过于繁重,所以在Activity中提炼出一个Presenter层,该层主要通过接口和View层交互,同时获得View层的反馈
优点
- 大大减轻了Activity的逻辑,将View和Presenter做分离,让项目更加简单明确
缺点
- 每个功能需要添加一个Presenter类,添加各种借口,增加开发量
- Presenter层持有Activity层的引用,需要注意内存泄漏或空指针的问题
MVVM
- View:View层
- ViewModel层:JetPack中的ViewModel组件,配合LiveData+DataBinding,保证View和ViewModel之间的交互,双向绑定,数据的更新可以实时绑定到界面中。
- Model层:数据层
ViewModel层中代替了Presenter的作用,里边做具体的逻辑,ViewModel与Activity的绑定通过反射构建,通过LiveData达到响应式,在Activity中调用ViewModel的逻辑,并实时更新到界面。
优点
- ViewModel+LiveData同Activity的生命周期绑定,当Avtivity不存在后,会销毁ViewModel,减少内存泄漏
- 提供Activity中多个Fragment的数据共享和逻辑调用
- 提供响应式编程,提供解决问题新方向
- 优秀的架构思想+官方支持=强大
- 代码量少,双向绑定减少UI的更新代码
缺点
- 降低了View的复用性,因为添加了很多DataBinding的代码,绑定到Activity中
- 难以定位bug,流程许多地方都是自动化更新,执行,无法确定当中哪一个环节出现问题(数据逻辑问题还是界面显示问题)
SharedPreferences commit apply使⽤区别
commit具有回调
apply将信息推送到主存,异步提交到文件,commit同步提交到文件
Bitmap解析
Bitmap是怎么存储图片的?
Bitmap是图片在内存中的表达形式,存储的是有限个像素点,每个像素点存储着ARGB值,代表每个像素所代表的颜色(RGB)和透明度(A)
Bitmap图片的内存是怎么计算的?
图片内存 = 宽 高 每个像素所占字节
每个像素所占字节和Bitmap.Config有关:
- ARGB_8888:常用类型,总共32位,4个字节,分别表示透明度和RGB通道。
- ARGB_4444:2个字节
- RGB_565:16位,2个字节,只能描述RGB通道。
- ALPHA_8:1个字节
Bitmap加载优化?不改变图片质量的情况下怎么优化?
- 修改Bitmap.Config,降低bitmap每个像素所占用的字节大小,替换格式为RGB_565,这样,内存直接缩小1倍
- 修改inSampleSize采样率,降低图片的大小,不影响图片的质量,控制每隔inSampleSize个像素进行一次采集
inSampleSize为1时,为原图大小。大于1时,比如2时,宽高就会缩小为原来的1/2
inSampleSize进行2的幂取整操作,1,2,4,8等
Bitmap内存复用怎么实现?
如果在一个imageView中加载多种不同的Bitmap图片,如果频繁的去创建bitmap,获取内存,释放内存,从而导致大量GC,内存抖动。
在使用Bitmap时,使用inBitmap配合inMutable参数,复用Bitmap内存。在4.4之前,只能复用内存大小相同的Bitmap,4.4之后,新Bitmap内存大小小于或等于复用Bitmap空间的,可以复用
高清大图如何加载?
使用BitmapRegionDecoder属性进行部分加载,根据界面滑动,不断更新部分图片的位置
intent可以传递bitmap吗?
可以,bitmap是parcelable序列化过的,也可以转化成byte[]进行传递
大小受限1M,因为binder的大小是1M,binder的线程数不大于16
Bitmap内存在各个android版本的存储?
Android Bitmap变迁与原理解析(4.x-8.x)
- 2.3版本之前:存储在本地内存中,不及时回收(recycler()方法),会触发OOM
- 2.3版本到7.0版本:像素数据和对象数据都存储在堆中
- 8.0以后:将对象存储在本地内存中(非java内存),通过NativeAllocationRegistry对bitmap进行回收
Fresco 对这个有详细的描述
深拷贝和浅拷贝
深拷贝:拷贝堆区中值
浅拷贝:拷贝堆区中的引用地址
创建一个对象的方式?
- 使用new关键字创建
- Class.newInstance反射创建
- Constructor.newInstance反射创建
- 利用clone方法实现(浅拷贝)
- 通过反序列化实现(深拷贝)
界面卡顿的原因
- UI线程存在耗时操作
- 视图渲染时间过长,导致卡顿
- 频繁gc,内存抖动
冷启动、温启动、热启动
冷启动:app首次启动,或者上次正常关闭后的启动,需要创建app的进程
- 启动系统进程。加载启动app进程,创建app进程
- 启动app进程任务。渲染屏幕,加载布局等
温启动:系统进程存在,app非正常关闭,只需要执行第二步,需要创建Activity或者重新布局等
热启动:热启动就是App进程存在,并且Activity对象仍然存在内存中没有被回收。所以热启动的开销最少,这个过程只会把Activity从后台展示到前台,无需初始化,布局绘制等工作
冷启动可以认为是android标准启动流程
Android类加载器
Android从ClassLoader中派生出两个类加载器:PathClassLoader和DexClassLoader
DexClassLoader:是一个可以从包含classes.dex实体的.jar或.apk文件中加载classes的类加载器。可以用于实现dex的动态加载、代码热更新等等。
PathClassLoader:可以操作在本地文件系统的文件列表或目录中的classes
DexClassLoader:能够加载未安装的jar/apk/dex
PathClassLoader:只能加载系统中已经安装过的apk
双亲委派
当一个类需要被初始化加载时,总会先把加载请求传递给父加载器,最终会传递到最高层加载器进行加载。父类加载器会检查是否加载过该类,如果没有加载过,则加载,若无法加载,会传递给子类加载器加载。
为何要使用双亲委派
- 首先明确,jvm认为不同加载器加载的类为两个不同的对象,所以为了系统安全性,需要保证相同的类要被同一个类加载器加载
- 避免了重复加载,如果父类加载过,直接使用父类加载过的类。
能不能自己写个类叫java.lang.System?
不可以,通过双亲委派该类名被加载为系统类,不会加载自己写的类。
如果非要实现这个效果,需要绕过双亲委派机制,实现自己的类加载器进行加载
插件化

PathClassLoader:只能加载已经安装到Android系统中的apk文件(/data/app目录),是Android默认使用的类加载器。
DexClassLoader:可以加载任意目录下的dex/jar/apk/zip文件,比PathClassLoader更灵活,是实现热修复的重点。
阿里系:DeXposed、andfix:从底层二进制入手(c语言)。阿里andFix hook 方法在native的具体字段。
art虚拟机上是一个叫ArtMethod的结构体。通过修改该结构体上有bug的字段来达到修复bug方法的目的,
但这个artMethod是根据安卓原生的结构写死的,国内很多第三方厂家会改写ArtMethod结构,导致替换失效。
腾讯系:tinker:从java加载机制入手。qq的dex插装就类似上面分析的那种。通过将修复的dex文件插入到app的dexFileList的前面,达到更新bug的效果,但是不能及时生效,需要重启。
但虚拟机在安装期间会为类打上CLASS_ISPREVERIFIED标志,是为了提高性能的,我们强制防止类被打上标志是否会有些影响性能
美团robust:是在编译器为每个方法插入了一段逻辑代码,并为每个类创建了一个ChangeQuickRedirect静态成员变量,当它不为空会转入新的代码逻辑达到修复bug的目的。
优点是兼容性高,但是会增加应用体积
- startActivity 的时候最终会走到 AMS 的 startActivity 方法
- 系统会检查一堆的信息验证这个 Activity 是否合法。
- 然后会回调 ActivityThread 的 Handler 里的 handleLaunchActivity
- 在这里走到了 performLaunchActivity 方法去创建 Activity 并回调一系列生命周期的方法
- 创建 Activity 的时候会创建一个 LoaderApk对象,然后使用这个对象的 getClassLoader 来创建 Activity
- 我们查看 getClassLoader() 方法发现返回的是 PathClassLoader,然后他继承自 BaseDexClassLoader
- 然后我们查看 BaseDexClassLoader 发现他创建时创建了一个 DexPathList 类型的 pathList对象,然后在 findClass 时调用了 pathList.findClass 的方法
- 然后我们查看 DexPathList类 中的 findClass 发现他内部维护了一个 Element[] dexElements的dex 数组,findClass 时是从数组中遍历查找的
sqlite怎么保证数据可见性和线程安全性?
sqlite不支持多个数据库连接进行写操作,但是使用同一个SQLiteHelper连接,可以进行多线程读和写,同一个连接下,sqlite内部有锁机制,不会出现异常,由于有锁的机制,所以是阻塞的,并不是真正的并发
延伸:SharedPreference是线程安全的,内部使用sychronized的
bundle的数据结构,为什么intent要使用bundle?
内部存储ArrayMap,key是int数组,value是object数组,使用Bundle传递对象和对象数组的时候会默认使用序列化,不用我们做处理。
key是hash值,value[]是存储的数据key值,和value值,采用二分法排序,使用二分法查找
优势:省内存,小数据上占优势。
大图传输
文件描述符是一个简单的整数,用以标明每一个被进程所打开的文件和socket。第一个打开的文件是0,第二个是1,依此类推。
socket:如果是网络中,会使用ip号+port号方式为套接字地址,但是如果同一台主机上两个进程间通信用套接字,还需要指定ip地址,有点过于繁琐. 这个时候就需要用到UNIX Domain Socket, 简称UDS,UDS不需要IP和Port, 而是通过一个文件名来表示
(int, (AF_UNIX,文件路径))
- 直接传输Bitmap,Bitmap实现Parcelable序列化,所以可以直接在内存中传输,所以可以直接通过Bundle传输过去,但是限制大小为1M。
- 可以存储在文件中,传输一个文件路径过去
- 使用Bundle的putBinder方法,通过Binder发送,其实putBinder传输过去的只是一个文件描述符fd,获取到fd后,从共享内存中获取到Bitmap
而用Intent/bundle直接传输的时候,会禁用文件描述符fd,只能在parcel的缓存区中分配空间来保存数据,所以无法突破1M的大小限制
webview
android调用js代码
- 通过loadUrl的方法直接调用js方法,会刷新页面,没有返回值
- evaluateJavascript()方法,android4.4以后使用,不会刷新页面,有返回值

js调用android代码
addJavascriptInterface()方法进行对象映射,
存在漏洞4.2以下创建一个类,使用@JavascriptInterface注解标识方法,使用addJavascriptInterface()为js创建对象
漏洞:
- 通过反射获取到这个类的所有方法和系统类,进行获取信息泄漏
- 4.2后添加注解避免漏洞攻击
webViewClient.shouldOverrideUrlLoading()拦截url
不存在漏洞在js中传入url,携带参数,拼接到url中,在shouldOverrideUrlLoading获取
触发js弹窗向android发消息。之后再回调中通过2方式的url传输消息

内存泄漏:加弱引用即可
要实现可以拖动的View该怎么做?
使用windowManager的updateViewLayout方法吗,实时传入手指的坐标就可以移动window1
2
3
4
5
6
7
8
9
10
11
12
13
14btn.setOnTouchListener { v, event ->
val index = event.findPointerIndex(0)
when (event.action) {
ACTION_MOVE -> {
windowParams.x = event.getRawX(index).toInt()
windowParams.y = event.getRawY(index).toInt()
windowManager.updateViewLayout(btn, windowParams)
}
else -> {
}
}
false
}
Android新知识
RxJava
响应式编程:根据响应去触发动作
使用观察者模式调用,使用于逻辑复杂的操作可以使用Rxjava做异步处理
- 按钮短300ms内不允许重复点击
1 | RxView.clicks(button).debounce(300, TimeUnit.MILLISECONDS).subscribe(new Action1<Void>() { |
- 轮询,定时执行
1 | //每隔两秒执行一次 |
- 消息传递,可取代EventBus
1 | //发布消息 |
Jetpack
一系列辅助android开发者的使用工具,统称Jetpack
提供新组件,比如导航组件,分页组件,切片组件等,例如mvvm中的LiveData,viewmodel都属于Jetpack组件
paging,room,livedata,viewmodel,lifecycler,compose,databinding,viewbinding
Jetpack在androidx中进行发布,androidx也属于Jetpack
AndroidX
androidx空间中包含Jetpack库,
之前使用android-support-v4(最低支持1.6) 和 android-support-v7(最低支持2.1)库做支持,androidx提出后,对support-v4 和 support-v7库不再做维护
MVVM

LiveData使用观察者模式观察生命周期,在onStart和onResume时回调onChanged,确保liveData对象内存泄漏。
DataBind 双向绑定,将view和model进行绑定,一方变化会导致另一方变化。
缺点:
- 难以排查bug,不知道是view的bug还是model的bug,bug会转移
- 不能复用view,因为绑定不同的model
LiveData+ViewModel替换EventBus
ViewBinding替换Butterknife
组件化,插件化,热修复
Kotlin理解
ConstraintLayout
Java基础篇
指令重排
as-if-serial
不管指令怎么重排序,在单线程下执行结果不能改变
happens-before
一个操作的执行结果需要对另一个操作可见,则两个操作之间必须存在happens-before关系,主要强调在多线程情况中
1 | public class ControlDep{ |
存在两个线程A,B,当A执行init发生了重排序,即先执行2,在执行1,当执行2时,B执行了use方法,但是B拿到的a还是0,所以i = 0,而正确的答案应该是i = 1
解决上面问题有两种方案:
- 内存屏障(volatile),禁止关于a的指令重排
- synchronized锁,锁住该对象或者该类
JVM内存模型
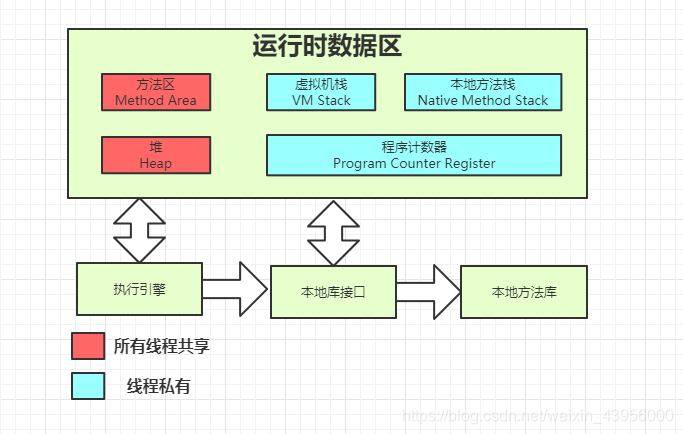
本地方法栈,程序计数器,虚拟机栈都是线程私有的,不存在线程安全
方法区和堆区,所有线程共享的,需要加锁保证线程安全
- 程序计数器:占用内存小,线程私有,生命周期与线程相同,大致为字节码行号指示器
- 虚拟机栈:java方法执行的内存模型,包含局部变量表,操作栈,动态链接,方法出口等信息,用于管理java方法的调用,使用连续的内存空间
- 本地方法栈:本地方法栈用于管理本地方法的调用
- 堆区:与jvm生命周期相同,存储所有的对象实例(包括数组)
- 方法区:存储已被加载的类信息,常量池,静态变量,即使编译器编译后的代码
静态变量创建在方法区,程序结束后回收,与堆无关
stack的大小默认为1M,如果是递归调用,大概只支持800多次
JVM内存模型的三大特性
原子性:多线程情况下,一旦一个线程开始执行,就不能被其他线程干扰
可见行:当一个线程修改了变量后及时更新到主存
有序性:处理器在执行运算的时候,会对程序代码进行乱序执行优化,也叫做重排序优化
垃圾回收机制
如何判断对象是个垃圾?
- 引用计数法
要操作对象必须使用引用,所以通过引用计数来判断对象是否需要被回收。因为无法解决循环引用的问题,所以JAVA中并没有采用这种方式(python中采用) - 可达性分析法
为了解决循环引用的问题,使用可达性分析。通过一系列的”GC ROOT”对象作为起点进行搜索,如果在”GC ROOT”和对象之间没有可达路径,那么该对象为不可达对象,并标记一次,标记两次后就会被回收。
“GC ROOT”:- 虚拟机栈中引用的对象(栈帧中的本地变量表);
- 方法区中的常量引用的对象;
- 方法区中的类静态属性引用的对象;
- 本地方法栈中JNI(Native方法)的引用对象。
- 活跃线程对象
垃圾回收机制是针对堆区的回收
比较常见的将对象判定为可回收变量
- 某个引用对象为null
1
2Object obj = new Object();
obj = null; - 已经指向某个对象的引用指向新的对象
1
2
3Object obj1 = new Object();
Object obj2 = new Object();
obj1 = obj2; - 局部引用所指向的对象循环每执行完一次,生成的Object对象都会成为可回收的对象。
1
2
3
4
5
6
7
8void fun() {
.....
for(int i=0;i<10;i++) {
Object obj = new Object();
System.out.println(obj.getClass());
}
} - 只有弱引用修饰的
1
WeakReference<String> wr = new WeakReference<String>(new String("world"));
垃圾回收算法
- 标记清除算法
将可回收对象标记后指定删除对象
缺点:产生大量内存碎片 - 复制算法
为了解决内存碎片的问题,提出复制算法。把内存按容量分成两份,当一份用完了,将还存活的对象复制在另一块对象中,把已使用的内存空间一次性清理掉
缺点:空间上的两倍消耗,可使用内存空间减半 - 标记整理算法
为了充分利用内存空间,在标记回收对象后,将存活对象向一端移动,然后清理掉端边界以外的内存 - 分代回收算法
将内存分为新生代,老年代和永久代。
新生代:
使用复制算法,回收大量对象,但不是按照1:1分配内存空间,将内存空间分为3份,较大的Eden和两块较小的Survivor空间,每次使用Eden和一块Survivor,当进行回收时,会将Eden和一块Survivor中存活的对象复制到另一个Survivor中。(比例为8:1:1)
老年代:
使用标记整理算法(和标记清除算法—-垃圾收集器种说),回收少量对象
永久代:
存在于方法区,不属于堆区,用来存储class类,常量,方法描述等,对永久代的回收主要包含两种:废弃常量和无用的类
注意: 在Java8中,永久代已经被移除,被一个称为“元数据区”(元空间)的区域所取代。
新生代 = 1/3的堆空间大小,老年代 = 2/3的对空间大小
新创建的对象都是在Eden区,大对象因为在新生代复制会影响性能,则直接创建在老年代
在Survivor中复制一次,就年龄计数+1,当年龄大大于15岁时,会移动到老年区
jdk7和jdk8上的JVM内存结构的变化?
jdk7:
在物理存储上,堆区和方法区是连续的,但是在逻辑上是分离的,因为物理存储上是存在一起的,所以在Full GC时,会触发堆永久代的回收
jdk8:
- 取消永久代,将类的结构等信息放入Native内存区,常量池和静态变量/全局变量存储在堆区
- 方法区存在元空间中,Native内存区就是元空间区
Native Memory(本地内存),空间不足,不会触发gc
为什么使用元空间替代永久代?
避免永久代的OOM发生,因为需要加载的类的总数,方法总数难以确定,分配的空间也难以确定,为了避免OOM,使用元空间,理论上可以获得本地内存中所有可用的空间
字符常量池存在那?
1.6:存储在方法区
1.7:对象存储在堆区中,引用存在字符串常量池,都在堆中
1.8:存储在堆区中
运行时常量池在哪?
1.8的时候移动到元空间中,之前都在方法区中
垃圾收集器
java种使用的是HotSpot虚拟机,HotSpot一共7种垃圾收集器,大致分为3类:
新生代收集器:Serial,ParNew,Parllel Scavenge
老年代收集器:Serial Old,CMS,Parllel Old
回收整个堆的G1收集器
- Serial(复制):新生代单线程收集器,在标记和清理都是单线程,优点是效率高,缺点是停留时间长。
- ParNew(复制):新生代并行收集器,Serial的多线程版本,在多核cpu环境下比Serial表现更好(只有他能和CMS配合)
- Parllel Scavenge(复制):新生代并行收集器,追求高吞吐量,高效利用CPU。尽快完成程序的运算任务,适合后台应用等对交互场景要求不高的场景。
吞吐量 = 用户线程时间/(用户线程时间+GC线程时间),缩短工作线程的等待时间 - Serial Old(标记-整理):老年代的单线程收集器,老年版的单线程
- Parllel Old(标记-整理):老年代的并行收集器,老年版的Parllel Scavenge
- CMS(Concurrent Mark Sweep)(标记-清除):老年代并行收集器,以获取最短回收停顿时间为目标,具有高并发,低停顿的特点。追求最短GC回收停顿时间,就是GC的时间更短
缺点:- 对CPU资源异常敏感,应用程序变慢,吞吐率下降
- 无法处理浮动垃圾。因为在标记和清除的时候,工作线程是运行的,所以期间会产生新的垃圾,但是本次无法回收。
- 产生大量内存碎片,会提前触发Full GC
- G1(Garbage First)(标记-整理):java并行收集器,G1的回收范围包含新生代和老年代。他用来作为下一代的收集器,保存新生代和老年代的概念,但是内部将Java堆划分为多个大小相等Region独立区域
优点:- 并行和并发。使用多个CPU缩短回收停顿时间,与用户线程并发执行
- 分带收集。独立去管理整个堆区间,能够采用不同的方式去处理新创建对象和已经存活了一段时间、熬过多次GC的旧对象,以获取更好的收集效果
- 使用标记-整理算法。无内存碎片产生。
- 可预测的停顿。可以使开发者制定一个时间长度,在该时间长度内,需要完成垃圾回收。
在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge收集器+Parallel Old收集器的组合
gc的种类和方式
- Minor GC:新生代GC
- 当Eden([‘id(ə)n])区放满的时候,触发Minor GC
- Major GC:老年代GC
- Full GC:全局GC(青年+老年)
- System.gc()方法有可能触发Full GC
- 老年代存储满了
- 永久代存储满了,触发Full GC,针对常量池的回收和类型的卸载
- Minor GC后放入老年代大小>老年代可用内存,即老年代放不下
- Minor GC后,放入一个1区中时,放不下,溢出来部分放入老年区,老年区放不下就会触发Full GC
GC会触发“stop-the-world”,即工作线程全部关闭,进行gc回收,当gc回收结束后,才会执行任务
HashMap
(1)美团面试题:Hashmap的结构,1.7和1.8有哪些区别,史上最深入的分析
简述
影响性能的两个参数:
- 初始容量:2的幂,默认是16
- 加载因子:什么时候扩容的标志,默认0.75,即16*0.75=12的时候开始hashmap扩容(容量为原来的2倍)
- 最大容量:2的30次方,如果大于,则使用2的30次方的大小
- 可以存储key == null,value == null,key == null则存储在table[0]位置
- 删除元素的本质是“删除单向链表的节点”
- Entry是单向链表
计算key的hash值,并将hash值添加到对应的链表中,若key存在,则更新vlaue值
1 | static class Node<K,V> implements Map.Entry<K,V> { |
和修改
- 因为是非synchronized的,非线程安全,所以比较快
- HashMap可以接受null键和null值
数组下标index的计算过程
1 | //数组长度-1 & hash值 |
同等于hash值对数组长度的求余
描述一下具体的put过程
- 对key求hash值,然后计算数组下标
- 如果数组下标没有碰撞,将Node放置在数组中
- 如果碰撞,将Node以链表的形式连接在后面
- 如果链表长度超过阈值(8),将链表转化为红黑树,链表长度低于6,则将红黑树转回链表
- 如果节点存在,则替换旧值
- 如果数组快满了(最大容量16*加载因子0.75),就需要resize(扩容两倍)
为什么选择6和8 ?
因为中间7的位置放置频繁的数据结构切换后,影响性能
get方法
- 计算key的hash,在计算index值
- 在数组中查找index值,在比对key值,取出value,复杂度最好是O(1),最坏为O(n)
为什么不直接使用红黑树?
空间和时间的选择,链短的时候空间上占用小,时间还好,转化为红黑树后,便于查找,但是耗费空间。
处理hash冲突的方法有以下几种:
- 开放地址法(线性探测再散列(碰撞后,位置后挪,数组长度+x)x可为正数,二次探测再散列(数组长度+x的平方)x可为正负数,平方后均为正数)
- 再哈希法(多种计算哈希的方法,相同则替换方法,直到算出不重复的哈希值)
- 链地址法(链表)
- 建立公共溢出区(建立一个溢出表,存放冲突的数据)
HashMap的性能慢原因?
- 数据类型自动装箱问题
- resize扩容重新计算index值和hashcode,重新赋值(1.7)
1.8后,扩容位置 = hash值 & 数组长度,如果为0,则不动,反之则反
线程不安全会导致什么
环状链表,resize(扩容)时头插法导致环形链表(1.7版本)
都存在数据丢失的问题数据丢失,1.8版本修复环形链表(尾插)
HashMap中默认容量为什么是2的幂?
因为如果不是2的幂,可能会造成更多的hash碰撞(index 下标碰撞)
假设n为17,n-1的二进制为10000,01001和01101算出的index值均为0
假设n为16,n-1的二进制为01111,01001和01101算出的index值不同
hashcode计算原理
对于int类型,hashcode为它本身,eg:int i = 1; hashcode = 1;
对于对象来说,hashcode是内部地址和对象值的一个映射
hash()算法原理
1 | static final int hash(Object key) { |
拿到key的hashCode(),在将该值与该值的高16位(h无符号右移16位)进行亦或运算(相同为0,不同为1)
HashTable的理解
put和get方法是用了synchronized修饰,锁住了整个map,同一时刻只有一个线程可以操作
不可以存储null值和null健
SparseArray理解
原理
装箱,int数据类型—->Integer对象,拆箱,Integer对象—->int数据类型
默认容量是10
- key是int值(避免装箱问题),使用二分查找寻找key,同样也是用二分插入,从小到大排列好的
- 两个数组,一组存放key(int []),一组存放value(object [])
1 | mKeys[i] = key; |
- 如果冲突,直接替换value的值
二分插入:
1 | while (lo <= hi) { |
第一个值放到最中间位置
第二个值如果大于中间的值放置在左边的中间位置
………….
put方法中,容量充足,计算key值所需存放的index,如果key相同,就直接替换value,如果不同,就insert数组,后续index元素后移,新key放置在index上
较HashMap的优点
- 节省内存
- 性能更好,避免装箱问题
- 数据量不达到千级,key为int值,可以用SparseArray替换HashMap
SparseArray与HashMap的比较,应用场景是?
- SparseArray采用的不是哈希算法,HashMap采用的是哈希算法
- SparseArray采用的是两个一维数组分别用于存储键和值,HashMap采用的是一维数组+单向链表/红黑树
- SparseArray key只能是int类型,而HashMap可以任何类型
- SparseArray key是有序存储(升序),而HashMap不是
- SparseArray 默认容量是10,而HashMap默认容量是16
- SparseArray 内存使用要优于HashMap,因为:
- SparseArray key是int类型,而HashMap是Object
- SparseArray value的存储被不像HashMap一样需要额外的需要一个实体类(Node)进行包装
- SparseArray查找元素总体而言比HashMap要逊色,因为SparseArray查找是需要经过二分法的过程,而HashMap不存在冲突的情况其技术处的hash对应的下标直接就可以取到值
针对上面与HashMap的比较,采用SparseArray还是HashMap,建议根据如下需求选取:
- 如果对内存要求比较高,而对查询效率没什么大的要求,可以是使用SparseArray
- 数量在百级别的SparseArray比HashMap有更好的优势
- 要求key是int类型的,因为HashMap会对int自定装箱变成Integer类型
- 要求key是有序的且是升序
ArrayMap的理解
内部也使用二分算法进行存储和查找,设计上更多考虑了内存中的优化
- int []存储hash值,array[index]存储key,array[index+1]存储value
数据量最好在千级以内
ArrayMap和SparseArray怎么进行选取?
- 如果key为int,那么选取SparseArray进行存储, 不存在封/拆箱问题
- 如果key不为int,则使用ArrayMap
TreeMap的理解
TreeMap是一个二叉树的结构,红黑树
不允许重复的key
TreeMap没有调优选项,因为其红黑树总保持在平衡状态
TreeMap和HashMap的区别?
- TreeMap由红黑树构成,HashMap由数组+链表/红黑树构成
- HashMap元素没有顺序,TreeMap元素会根据可以进行升序排序
- HashMap进行插入,查找,删除最好,TreeMap进行自然顺序便利或者自定义顺序便利比较好
ThreadLocal的理解
面试官:小伙子,听说你看过ThreadLocal源码?(万字图文深度解析ThreadLocal)
线程隔离,数据不交叉
- ThreadLocalMap,每个thread都存在一个变量ThreadLocalMap threadLocals
- threadLocalMap中存在Entry,同ThreadLocal之间为弱引用关系
- ThreadLocalMap中key为ThreadLocal的弱引用,value为Entry,内部为一个object对象
- table默认大小为16,存在初始容量(16)和阈值(16*2/3)
- 在ThreadLocal中使用get()和set()方法初始化threadLocals
- get、set、remove方法将key==null的数据清除
- table是环形数组
线性探测法避免哈希冲突,增量查找没有被占用的地方
通过hashcode计算索引位置,如果key值相同,则替换,不同就nextIndex,继续判断,直到插入数据
ThreadLocal就是管理每个线程中的ThreadLocalMap,所以线程隔离了。
ThreadLocalMap的理解
新建ThreadLcoal的时候,创建一个ThreadLocalMap对象,计算hash的时候使用0x61c88647这个值,他是黄金分割数,导致计算出来的hash值比较均匀,这样回大大减少hash冲突,内部在采用线性探测法解决冲突
set:
- 根据key计算出数组索引值
- 遍历该索引值的链表,如果为空,直接将value赋值,如果key相等,直接更新value,如果key不相等,使用线性探测法再次检测。
ThreadLocal使用弱引用的原因
key使用了弱引用,如果key使用强引用,那么当ThreadLocal的对象被回收了,但ThreadLocalMap还持有ThreadLocal的强引用,回导致ThreadLocal不会被回收,导致内存泄漏
ThreadLocal的内存泄漏
- 避免使用static修饰ThreadLocal:延长生命周期,可能造成内存泄漏
- ThreadLocal弱引用被gc回收后,则key为null,object对象没有被回收,只有当再次调用set,get,remove方法的时候才会清楚key为null的对象
ThreadLocalMap清理过期key的方式
- 探测式清理
本该放在4的位置上的值,放到了7的位置上,当5过时后,将7的数据挪到5的位置上 - 启发式清理
遍历数组,清理数据
ConcurrentHashMap和HashMap的区别
jdk 1.7 ReentrantLock+segments + hashEntry(不可变)

- 线程安全,分段线程锁,hashtable是整段锁,所以性能有所提高
- 默认分配16个锁,比Hashtable效率高16倍
- hashEnty是final的,不能被修改,只要被修改,该节点之前的链就要重新创建,采用头插插入,所以顺序反转
- 获取size,因为是多线程访问,所以size会获取三遍,如果前后两个相等就返回,假设不相等,就将Segment加锁后计算。
jdk 1.8 : synchronized +node+volatile+红黑树
put:
- 根据key的hash值算出Node数组的相应位置
- 如果该Node不为空,且当前该节点不处于移动状态,则对节点加synchronized锁,进行遍历节点插入操作
- 如果是红黑树节点,向红黑树插入操作
- 如果大于8个,拓展为红黑树
get:
- 计算hash值,定位到该table索引位置,如果是首节点符合就返回
- 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,通知在新表中查找该节点,匹配就返回
- 以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
1.7和1.8的区别:
1.7:ReentrantLock+segments + hashEntry(不可变)
1.8:synchronized +node+volatile+红黑树1.8的锁的粒度更低,锁的是一个链表(table[i]),而1.7锁的是一个小的hashmap(segement)
- ReentrantLock性能比synchronized差
扩容:
1.7下进行小HashMap(segement)扩容操作
1.8下使用synchrozied节点加锁,所以可以通过多个线程扩容处理。一个线程创建新的ConcurrentHashMap,并设置大小,多个线程将旧的内容添加到新的map中,如果添加过的内容就会设置标记,其他线程就不会处理
为什么只有hashmap可以存储null值和null键
因为hashmap是线程不安全的,而在其他中都是线程安全的,在多线程访问时,无法判断key为null是没有找到,还是key为null
锁
常见锁
锁的分类
公平锁/非公平锁
- 公平锁:多个线程按照申请锁的顺序获取锁。
- 非公平锁:多个线程申请锁并不是按照顺序获取锁,有可能先申请后获取锁。(Synchronized)
ReentrantLock默认是非公平锁,通过构造传参可设置为公平锁。非公平锁的优点在于吞吐量比公平锁大
- 可重入锁:又名递归锁,指在外层方法获取锁以后,在进入内层方法也会自动获取锁。如果不是可重入锁,那么setB方法不会被当前线程执行,容易造成死锁
1
2
3
4
5
6
7
8synchronized void setA() throws Exception(){
Thread.sleep(1000);
setB();
}
synchronized void setB() throws Exception(){
Thread.sleep(1000);
}synchronized是可重入锁
- 独享锁/共享锁
- 独享锁:一个锁一次只能被一个线程所持有(ReentrantLock,synchronized)
- 共享锁:一个锁被多个线程所持有。(ReadWriteLock)
- 互斥锁/读写锁
上面讲的独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。
互斥锁在Java中的具体实现就是ReentrantLock
读写锁在Java中的具体实现就是ReadWriteLock - 乐观锁/悲观锁
- 悲观锁:对同一数据的并发操作,一定会发生修改的。(利用各种锁实现)
- 乐观锁:对同一数据的并发操作,一定不会发生修改的。(无锁编程,CAS算法,自旋实现原子操作的更新)
- 分段锁
是一种锁的设计,并不是具体的锁,在1.7版本的ConcurrentHashMap中,使用分段锁设计,该分段锁又称为Segment,map中每一个链表由ReentrantLock修饰 偏向锁/轻量级锁/重量级锁
这三种锁是描述synchronized的三种状态。- 偏向锁:一段同步代码一直被一个线程访问,那么会自动获取锁,降低获取锁的代价
- 轻量级锁:当锁是偏向锁的时候,被另一个线程访问,偏向锁会升级为轻量级锁,其他线程通过自旋的方式获取锁,不会阻塞,提高性能
- 重量级锁:在轻量级锁的基础上,自旋达到上限就会阻塞,升级为重量级锁,会让其他线程进入阻塞,影响性能。
锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后无法降为偏向锁,这种升级无法降级的策略目的就是为了提高获得锁和释放锁的效率。
- 自旋锁
获取锁的过程中,不会立即阻塞,会采用循环的方式获取锁,减少线程切换上下文的消耗,缺点是循环会消耗cpu
java中常用锁的类型
- synchronized:非公平,悲观,独享,互斥,可重入,重量级锁
- ReentrantLock:默认非公平(可公平),悲观,独享,互斥,可重入,重量级锁
CAS,全称为Compare-And-Swap,是一条CPU的原子指令,其作用是让CPU比较后原子地更新某个位置的值,实现方式是基于硬件平台的汇编指令,就是说CAS是靠硬件实现的,JVM 只是封装了汇编调用,那些AtomicInteger类便是使用了这些封装后的接口。
synchronized和volatile
简述synchronized的原理
可见性:表示A修改的值对于B执行时可以看见A修改后的值
- 内部使用monitorenter指令,同时只有一个线程可以获取monitor
- 未获取monitor的线程会被阻塞,等待获取monitor
- 线程A获取主内存值后加锁,在本地内存更新值(临时区)后,推送到主内存,通过synchronized隐式通知线程B访问主存获取值,在B的把本地内存更新值后推送到主存,重复以上操作。
通过Monitor对象来实现方法和代码块的同步,存在monitorEnter和monitorExit指令,插入程序中,在一个线程访问时,通过Monitor进行线程阻塞
synchronized修饰静态方法、⾮静态方法区别
静态方法:该类的对象,new出来的多个实例对象是被一个锁锁住的,多线程访问需要等待
非静态方法:实例对象
volatile
修饰成员变量,保证可见性,下一个操作再上一个操作之上。++操作不保证和原子性,
将本地缓存同步到主存中,使其他本地缓存失效,本地缓存通过嗅探检查自己的缓存是否过期。(下一次访问,主存不会主动通知)
volatile无法保证原子性,可以使用乐观锁的重试机制进行优化
synchronized和volatile区别
Synchronized 引起线程阻塞,而volatile不会
区别在于,synchronized是隐式通知B去主存获取值,volatile是B主动通过嗅探的方法发现自己的内存过期后去主存做同步
synchronized:先清空工作内存→在主内存中拷贝最新变量的副本到工作内存→执行完代码→将更改后的共享变量的值刷新到主内存中→释放互斥锁。
都存在可见性,但是volatile不具备原子性,所以不会造成线程阻塞
假设某一时刻i=10,线程A读取10到自己的工作内存,A对该值进行加一操作,但正准备将11赋给i时,由于此时i的值并未改变,B读取了主存的值仍为10到自己的工作内存,并执行了加一操作,正准备将11赋给i时,A将11赋给了i,由于volatile的影响,立即同步到主存,主存中的值为11,并使得B工作内存中的i失效,B执行第三步,虽然此时B工作内存中的i失效了,但是第三步是将11赋给i,对B来说,我只是赋值操作,并没有使用i这个动作,所以这一步并不会去刷新主存,B将11赋值给i,并立即同步到主存,主存中的值仍为11。虽然A/B都执行了加一操作,但主存却为11,这就是最终结果不是10000的原因。
synchronized修饰方法,类,变量,代码块,volatile只能修饰变量
synchronized修饰不同对象的区别
- 修饰类:作用的对象是这个类的所有对象
- 方法:作用对象是这个方法的对象
- 静态方法:作用对象是这个类的对象
- 代码块:作用对象是这个代码块的对象
悲观锁和乐观锁(CAS)
悲观锁:当前线程获得锁会阻塞其他线程(sychronized)
乐观锁:不会添加锁,会存在三个值内存实际值,内存的旧值,更新的新值,如果内存实际值和旧值相等,则没有线程修改该值,将更新的新值直接赋值给内存,如果不相等,就重新尝试赋值操作(volatile)
CAS的缺点:
- ABA问题,A->B->A,乐观锁认为没有变化,都是A,所以直接赋值
- 重新赋值的话,会导致时间过长。
ReentrantLock
CAS+AQS实现,乐观锁
AQS(单链表队列)维护一个等待队列,将获取不到锁的线程放入到队列中进行等待,当当前线程执行结束后,进行出队操作,使用一个volatile的int成员变量(state)来表示同步状态
通过ReentrantLock的Lock方法进行加锁
通过ReentrantLock的unLock方法进行解锁
线程
新建线程有几种方式?
- new Thread
- 新建Runnable对象
- 新建Callable或者Future对象
- 线程池使用
new Thread的弊端
执行一个异步任务你还只是如下new Thread吗?
new Thread的弊端如下:
- 每次new Thread新建对象性能差。
- 线程缺乏统一管理,可能无限制新建线程,相互之间竞争,及可能占用过多系统资源导致死机或oom。
- 缺乏更多功能,如定时执行、定期执行、线程中断。
相比new Thread,Java提供的四种线程池的好处在于:
- 重用存在的线程,减少对象创建、消亡的开销,性能佳。
- 可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
- 提供定时执行、定期执行、单线程、并发数控制等功能。
线程池
线程的5种状态
- NEW:创建一个新线程
- RUNNABLE:可运行
- BLOCKED:阻塞
- WAITING:进入等待状态
- TIMED_WAITING:等待结束,重新获取锁
- TERMINATED:结束
- RUNNING:运行中
- READY:就绪

一般来说分为五大状态:
- 新建(New):
创建线程对象,进入新建状态。eg:Thread thread = new Thread(); - 就绪(Runnable):
调用thread.start()方法,随时可被cpu执行 - 运行(Runnable):
CPU执行线程 - 阻塞(Blocked):
出于某些原因,cpu放弃线程执行,线程进入暂停状态- 等待阻塞:调用wait方法,进行阻塞,线程等待某工作完成
- 同步阻塞:在获取Synchronized同步锁时,进行等待
- 其他阻塞:通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
- 死亡(Dead):
堪称执行完毕或者因异常退出,线程死亡,回收
start和run的区别?sleep和wait的区别?join,yield,interrupt
- start是启动一个线程
- run只是Thread的实现方法,主要实现是Runnable的接口回调run方法
- sleep不会释放对象锁,只是暂停了线程的运行,当指定时间到了,就恢复运行状态
- wait方法放弃对象锁,只有调用了notify()方法,才会重新获取锁,进入运行状态
- join方法是规定线程的执行顺序,如果在B线程中调用了A的join方法,那么,直到A执行完毕,才会执行B,按照顺序串行执行。实际内部方法是调用了wait方法,让B处于等待状态,A执行完成后,启动B
注意:wait方法是调用u哦在线程放弃对象锁,所以在B线程调用A的join方法,只是让B等待了。
- yield方法,通知cpu该线程任务不紧急,可以被暂停让其他线程运行
- interrupt方法,中断通知线程,具体操作由线程执行,根据不同状态,执行不同逻辑
线程t1、t2、t3,如何保证他们顺序执行?
t3开始中调用t2.join(),t2开始中调用t1.join()。
t1执行完毕后,t2中t1.join()方法不阻塞,即t1执行完,执行t2中的方法,后续类似
使用CountDownLacth,进行计数
1 | public static void main(String[] args) { |
什么是死锁
资源竞争互相等待
假设线程A,线程B,资源A,资源B
线程A访问资源A,持有资源A锁,线程B访问资源B,持有资源B锁,而后线程A要访问资源B,但是线程B持有资源B锁,线程A等待,线程B要访问资源A,但是线程A持有资源A锁。所以B等待。
结果就是A、B相互等待对方释放资源,造成死锁。
一个线程崩溃会影响其他线程吗?
不一定。
如果崩溃发生在堆区(线程共享区域),会导致其他线程崩溃。
如果崩溃发生在栈区(线程私有区域),不会导致其他线程的崩溃
java反射
- 反射类及反射方法的获取,都是通过从列表中搜寻查找匹配的方法,所以查找性能会随类的大小方法多少而变化;
- 每个类都会有一个与之对应的Class实例,从而每个类都可以获取method反射方法,并作用到其他实例身上;
- 反射也是考虑了线程安全的,放心使用;
- 反射使用软引用relectionData缓存class信息,避免每次重新从jvm获取带来的开销;
- 反射调用多次生成新代理Accessor, 而通过字节码生存的则考虑了卸载功能,所以会使用独立的类加载器;
- 当找到需要的方法,都会copy一份出来,而不是使用原来的实例,从而保证数据隔离;
- 调度反射方法,最终是由jvm执行invoke0()执行;
使用反射从jvm中的二进制码文件中读取数据
反射原理
.java–>.class–>java.lang.Class对象
编译过程:
- 将.java文件编译成机器可以识别的二进制文件.class
- .class文件中存储着类文件的各种信息。
比如版本号、类的名字、字段的描述和描述符、方法名称和描述、是不是public、类索引、字段表集合,方法集合等等数据 - JVM从二进制文件.class中取出并拿到内存解析
- 类加载器获取类的二进制信息,并在内存中生成java.lang.Class对象
- 最后开始类的生命周期并初始化(先静态后非静态和构造,先父类在子类)
而反射操作的就是内存中的java.lang.Class对象。
总结来说.class是一种有顺序的结构文件,而Class对象就是对这种文件的一种表示,所以我们能从Class对象中获取关于类的所有信息,这就是反射的原理。
为什么反射耗时?
- 校验时间长
- 基本类型的封箱和拆箱
- 方法内联
什么是内联函数?
方法调用过多会进行内敛优化,减少方法的嵌套层级,加快执行,缓解栈的空间存储
反射可以修改final类型的成员变量吗?
已知final修饰后不会被修改,所以获取这个变量的时候就直接帮你在编译阶段就给赋值了
编译器将指定的函数体插入并取代每一处调用该函数的地方(上下文),从而节省了每次调用函数带来的额外时间开支。
所以上述的getName方法经过JVM编译内联优化后会变成:1
2
3
4
5
6
7
8public String getName() {
return "Bob";
}
//打印出来也是Bob
System.out.println(user.name)
//经过内联优化
System.out.println("Bob")
反射是可以修改final变量的,但是如果是基本数据类型或者String类型的时候,无法通过对象获取修改后的值,因为JVM对其进行了内联优化。
反射可以修改static值吗?
1 | Field.get(null) 可以获取静态变量。 |
Java异常
简析
java中的异常分为2大类,Error和Exception。Error中有StackOverFlowError和OutOfMemoryError。Exception分为IOException和RuntimeException。
Java中检查型异常和非检查型异常有什么区别?
检查型异常 extends Exception(编译时异常):需要使用try catch进行捕获,否则会出错,继承自Exception
非检查型异常 extends RuntimeException(运行时异常):不需要捕获,在必要时才会报错,
try-catch-finally-return执行顺序?
- 不管是否有异常产生,finally块中代码都会执行
- 当try和catch中有return语句时,finally块仍然会执行
- finally是在return后面的表达式运算执行的,所以函数返回值在finally执行前确定的,无论finally中的代码怎么样,返回的值都不会改变,仍然是之前return语句中保存的值
- finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值
throw和throws的区别
throw用在方法内部,抛出异常
throws用在方法外部,在方法中抛出异常
栈溢出StackOverFlowError发生的几种情况?
递归,栈内存存满,函数调用栈太深
Java常见异常有哪些
java.lang.IllegalAccessError:违法访问错误。当一个应用试图访问、修改某个类的域(Field)或者调用其方法,但是又违反域或方法的可见性声明,则抛出该异常。
java.lang.InstantiationError:实例化错误。当一个应用试图通过Java的new操作符构造一个抽象类或者接口时抛出该异常.
java.lang.OutOfMemoryError:内存不足错误。当可用内存不足以让Java虚拟机分配给一个对象时抛出该错误。
java.lang.StackOverflowError:堆栈溢出错误。当一个应用递归调用的层次太深而导致堆栈溢出或者陷入死循环时抛出该错误。
java.lang.ClassCastException:类造型异常。假设有类A和B(A不是B的父类或子类),O是A的实例,那么当强制将O构造为类B的实例时抛出该异常。该异常经常被称为强制类型转换异常。
java.lang.ClassNotFoundException:找不到类异常。当应用试图根据字符串形式的类名构造类,而在遍历CLASSPAH之后找不到对应名称的class文件时,抛出该异常。
java.lang.ArithmeticException:算术条
件异常。譬如:整数除零等。
java.lang.ArrayIndexOutOfBoundsException:数组索引越界异常。当对数组的索引值为负数或大于等于数组大小时抛出。
java.lang.IndexOutOfBoundsException:索引越界异常。当访问某个序列的索引值小于0或大于等于序列大小时,抛出该异常。
java.lang.InstantiationException:实例化异常。当试图通过newInstance()方法创建某个类的实例,而该类是一个抽象类或接口时,抛出该异常。
java.lang.NoSuchFieldException:属性不存在异常。当访问某个类的不存在的属性时抛出该异常。
java.lang.NoSuchMethodException:方法不存在异常。当访问某个类的不存在的方法时抛出该异常。
java.lang.NullPointerException:空指针异常。当应用试图在要求使用对象的地方使用了null时,抛出该异常。譬如:调用null对象的实例方法、访问null对象的属性、计算null对象的长度、使用throw语句抛出null等等。
java.lang.NumberFormatException:数字格式异常。当试图将一个String转换为指定的数字类型,而该字符串确不满足数字类型要求的格式时,抛出该异常。
java.lang.StringIndexOutOfBoundsException:字符串索引越界异常。当使用索引值访问某个字符串中的字符,而该索引值小于0或大于等于序列大小时,抛出该异常。
linux进程通信有几种
Linux中的进程间通信有哪些?解释Binder通信为什么高效?Binder通信有什么限制?
Linux中的进程间通信有如下几种:
- 信号(signal)
- 消息队列
- 共享内存(Shared Memory)
共享内存允许两个或多个进程进程共享同一块内存(这块内存会映射到各个进程自己独立的地址空间)从而使得这些进程可以相互通信。 - 管道/命名管道(Pipe)
Pipe这个词很形象地描述了通信双方的行为,即进程A与进程B。一根管道同时具有读取端和写入端。比如进程A从write end写入,那么进程B就可以从read end读取数据。 - Socket
本地和服务端各自维护一个“文件”,在建立连接打开后,向自己的文件中写入数据,供对方读取
Binder通信是Android系统特有的IPC机制,Binder的优点有以下几个:
- 性能:Binder的效率高,只需要一次内存拷贝;而Linux中的管道、消息队列、套接字都需要2次;共享内存的方式不需要拷贝数据,但是有多进程同步的问题。
- 稳定性:Binder的架构是基于C/S结构,客户端(Client)有什么需求就丢给服务端(Server)去完成,架构清晰、职责明确又相互独立,自然稳定性更好。共享内存虽然无需拷贝,但是控制负责,难以使用。从稳定性的角度讲,Binder 机制是优于内存共享的。
- 安全性:传统的 IPC 接收方无法获得对方可靠的进程用户ID/进程ID(UID/PID),从而无法鉴别对方身份。Android 为每个安装好的 APP 分配了自己的 UID,故而进程的 UID 是鉴别进程身份的重要标志。Android系统中对外只暴露Client端,Client端将任务发送给Server端,Server端会根据权限控制策略,判断UID/PID是否满足访问权限。从安全角度,Binder的安全性更高。
Binder通信的另外一个限制是最多16个线程。最多只能传输1M的数据,否则会有TransactionTooLarge的Exception。
CountDownLatch原理
存在4个线程,想在4个线程都执行完毕后执行另一个线程,
countDownLatch是采用计数器的原理,存在两个方法:
countDown:计数-1
await:线程挂起,当计数为0时,执行其后的逻辑
Java泛型
泛型简述
java中泛型即是“参数化类型”,即该泛型类型是一个参数传入
只在程序的源代码中存在,在编译后的字节码中已经替换为原生类型,这种方法称为伪泛型。
java中的泛型只在编译时期有效,正确检验泛型的结果后,会将泛型相关的信息擦出,并在对象进入和离开的方法边界上添加类型检查和类型转化的方法。
1 | List<String> stringArrayList = new ArrayList<String>(); |
泛型有泛型类、泛型方法和泛型接口
泛型类:
1 | //此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型 |
泛型接口:
1 | //定义一个泛型接口 |
泛型方法:
1 | /** |
泛型对方法重载的影响?
方法不能进行重载,会报错,两种方法都有相同的擦除,在编译期间进行泛型擦除的,会导致擦出后都一样
1 | public class MyMethod { |
类加载
java类的初始化流程
父类到子类,静态到(非静态,构造),变量—–>代码块
父类静态变量—-父类静态代码块—-子类静态变量—-子类静态代码块—-父类非静态—-父类构造—-子类非静态—-子类构造
jvm类加载机制的7个流程
加载—–验证——准备——解析——初始化——-使用——卸载
JVM将.java文件加载成二进制文件.class
加载:
- 获取二进制流class文件
- 将静态存储结构转换为方法区中运行时的数据结构,存储到方法区中
- 在堆中生成一个java对象,作为方法区的引用
获取.class文件并在堆中生成一个class对象,将加载的类结构信息存储在方法区
验证:JVM规范校验,代码逻辑校验
准备:为类变量分配内存并设置类变量的初始化,如果变量被final修饰,会直接放入对应的常量池中,并赋值
解析:常量池符号引用替换为内存的直接引用
(上述三种统称为连接)
初始化:执行代码逻辑,对静态变量,静态代码块和类对象进行初始化
使用:使用初始化好的class对象
卸载:销毁创建class对象,负责运行的jvm退出内存
全局变量和局部变量的区别
- 全局变量应用于整个类文件。局部变量只在方法执行期间存在,之后被回收。静态局部变量对本函数体始终可见
- 全局变量,全局静态变量,局部静态变量都在静态存储空间。局部变量在栈(虚拟机栈)中分配空间
- 全局变量初始化需要赋值,局部变量不需要赋值
- 一个类中不能声明同名全局变量,一个方法中不能声明同名局部变量。若全局变量和局部变量同名,则在方法中全局变量不生效。
大致流程
当JVM碰到new字节码的时候,会先判断类是否已经初始化,如果没有初始化(有可能类还没有加载,如果是隐式装载,此时应该还没有类加载,就会先进行装载、验证、准备、解析四个阶段),然后进行类初始化。
如果已经初始化过了,就直接开始类对象的实例化工作,这时候会调用类对象的
类初始化的时机
- 初始化main方法的主类
- new 关键字触发,如果类还没有被初始化
- 访问静态方法和静态字段时,目标对象类没有被初始化,则进行初始化操作
- 子类初始化过程中,如果发现父类没有初始化,则先初始化父类
- 通过反射API调用时,如果类没有初始化,则进行初始化操作
- 第一次调用java.lang.invoke.MethodHandle 实例时,需要初始化 MethodHandle 指向方法所在的类。
类的实例化触发时机
- new 触发实例化,创建对象
- 反射,class.newnIstance()和constructor.newnIstance()方法触发创建对象
- Clone方法创建对象
- 使用序列化和反序列化的机制创建对象
类的初始化和类的实例化的区别
类的初始化:为静态成员赋值,执行静态代码块
类的实例化:执行非静态方法和构造方法
- 类的初始化只会执行一次,静态代码块只会执行一次
- 类的实例化会执行多次,每次实例化执行一次
在类都没有初始化完毕之前,能直接进行实例化相应的对象吗?
正常情况下是先类初始化,再类实例化
在非正常情况下,比如在静态变量中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class Run {
public static void main(String[] args) {
new Person2();
}
}
public class Person2 {
public static int value1 = 100;
public static final int value2 = 200;
public static Person2 p = new Person2();
public int value4 = 400;
static{
value1 = 101;
System.out.println("1");
}
{
value1 = 102;
System.out.println("2");
}
public Person2(){
value1 = 103;
System.out.println("3");
}
}
执行public static Person2 p = new Person2();这样就会直接实例化,然后在执行类的初始化,所以会打印1
23123
多线程进行类的初始化会出问题吗?
不会,类初始化
一个实例变量在对象初始化的过程中最多可以被赋值几次?
4次
- 对象被创建时候,分配内存会把实例变量赋予默认值,这是肯定会发生的。
- 实例变量本身初始化的时候,就给他赋值一次,也就是int value1=100。
- 初始化代码块的时候,也赋值一次。
- 构造函数中,在进行赋值一次。
1
2
3
4
5
6
7
8
9
10
11
12
13public class Person3 {
public int value1 = 100;
{
value1 = 102;
System.out.println("2");
}
public Person3(){
value1 = 103;
System.out.println("3");
}
}
屏幕
高刷手机,60hz,120hz指的是什么?
屏幕刷新率,1s内屏幕刷新的次数。这个参数由手机硬件决定
一般大于60hz的就是高刷收集,特点在于刷新频率更高,就算存在丢帧、卡顿,也能保持稳定性。
屏幕的刷新过程
从左到右,从上到下,顺序显示像素点。当整个屏幕刷新完毕,即一个垂直刷新周期后,(1000/60)16ms后再次刷新
一般一个图形界面的绘制,需要CPU准备数据,然后GPU进行绘制,绘制完写入缓存区,然后屏幕按照刷新频率来从这个缓存区中取图形显示。
所以整个刷新过程是CPU,GPU,屏幕(Display)三方合作的工作关系。
帧率,VSYNC是什么
帧率:GPU一秒内渲染绘制的操作的帧数,单位是fps,所以一般帧数和屏幕刷新度保持一致是效果最好的情况,不会导致一方浪费
VSYNC:垂直同步,作用是让帧率和屏幕刷新率保持一致,防止卡顿和跳帧。由于CPU和GPU绘制图像的时间不稳定,所以可能会发生卡顿情况,也就是下一帧的数据还没准备好无法正常显示在屏幕上,设置垂直同步后,要求CPU和GPU在16ms之内将下一帧的数据处理好,那么屏幕刷新的时候就可以直接从缓存中获取下一帧的数据并显示出来
屏幕中单缓存,双缓存,三缓存
- 单缓存:CPU计算好数据传递给GPU,GPU图像绘制后放到缓存区,display从缓存中获取数据并刷新屏幕
缺点:当第二帧的数据还没生成完成时,会导致屏幕中有一部分第一帧的数据,导致一个屏幕同时显示了两帧的数据 - 双缓存:CPU计算好数据传递到GPU,GPU图像会之后放入缓存区BackBuffer,当到达VSYNC垂直同步时间,将数据同步到缓存区FrameBuffer中,display从缓存区FrameBuffer中获取数据并显示
缺点:如果在一个垂直同步的时间内CPU+GPU没有渲染完成(开始绘制的时间在下次垂直同步时间附近,导致只有一小份垂直同步时间在绘制),就会浪费一个VSYNC垂直同步时间,当VSYNC垂直同步时间来临时,GPU正在处理数据,那么不会开启下一帧的处理,当GPU处理结束后,无法触发下一帧的数据处理,就会导致卡顿的情况 - 三缓存数据:当在一个垂直同步时间内没有完成处理,就会出现第三个缓存区,在第二个垂直同步时间,缓存下一帧的数据,这样两个缓存交替处理,保证FrameBuffer会拿到最新的数据,保证了显示的流畅度
代码中修改了UI,屏幕是怎么进行刷新的?
当调用invalidate/requestLayout中进行重绘工作时,会向VSYNC垂直同步服务请求,等待下一次VSYNC垂直同步时间,执行界面绘制刷新操作,CPU->GPU->Display
如果界面保持静止不变,屏幕会刷新吗?图像会被重新绘制吗?
屏幕不会刷新,不会重新绘制,如果屏幕不变,程序就收不到垂直同步时间,自动过滤,不处理屏幕刷新操作,只有当界面改变时,才会请求VSYNC垂直同步服务,触发下一次VSYNC垂直同步刷新屏幕
jvm垃圾回收机制
首先介绍4个引用
强引用:在使用时不会被回收
软引用:系统内存不足时会被回收
弱引用:下一次gc会被回收
虚引用:任何时候都可能被回收
小知识点
抽象类和接口的区别
- 抽象类中可包含普通方法+实现,接口类中只存在抽象方法,没有具体实现
- 抽象类中的值可以是任何类型的,接口中的值必须是public static final修饰的
- 一个类只能继承一个抽象类,一个类可以实现多个接口类
- 抽象类存在构造函数,接口类没有
- 抽象类中包含初始化块,接口中没有
static和final的区别
static
是可以直接调用的(类名.方法/变量),
可修饰属性,方法,代码段,内部类
所有对象只有一个值
final
可修饰属性,方法,类,局部变量
final修饰变量不可被更改值,方法不能被重写,类不能被继承
修饰集和的话,其引用不变,集和可以自由变化
java是值传递还是引用传递
如果是基本类型就是值传递
引用类型就是引用传递
String表现为值传递,但是其实是作为形参后重新创建了对象,引用已经变化,所以是值传递
1 | public void test() { |
1 | public void test() { |
String、StringBuilder、StringBuffer的区别
String是不可变的,每次赋值都是重新创建对象,对内存和性能都有损耗
StringBuilder是非线程安全的,存储通过一个可变长度的字符数组(char[])。
append值时,如果所需长度大于分配长度,新建数组长度为(2倍+2),如果所需长度大于(2倍+2),则使用所需长度大小,否则,使用(2倍+2)长度,默认长度为16,有参构造=16+参数长度
StringBuffer是线程安全的
效率上由快到慢:StringBuilder > StringBuffer > String
String为什么是final(不可变)的?
final+private保证了其不可修改性
- 不可变性保证了线程安全
- 不可变后避免了深拷贝,将String值放在字符串常量池(堆内)中,供其他方引用,提高效率,节约内存
hashcode、equals和== 的区别?
hashcode:
- 基本类型就是改值
- 引用类型是对象在内存地址的映射
equals:
- 在object中equals方法等效于==
- 在其他方法中,重写了equals方法,会判断值是否相等
==:
- 基本类型比对的是值
- 引用对象比对的是内存地址的映射
对于String,Integer对象,他们重写了equals方法,所以其equals方法可以判断值是否相等,而==只能判断引用是否相等
进程,线程,协程的区别?阻塞和非阻塞的区别?
进程
进程包含线程
进程是CPU分配资源的最小单位
线程
线程包含协程
线程是独立运行和独立调度的基本单位(CPU上真正执行的是线程)
线程间共享进程内资源
线程的调度切换比进程快
协程
协程是存在线程之上,通过异步IO处理执行多个协程的操作
协程的调度切换比线程快
阻塞与非阻塞
阻塞就是线程被cpu挂起,不执行线程逻辑
非阻塞就是线程不被cpu挂起,执行线程逻辑
并发和并行
并发是你执行一下,我执行一下,轮着执行
并行是一起执行
协程和线程的比较
- 协程运行在线程之上
- 线程执行由内核控制(内核态执行),控制线程切换消耗资源(抢先式),协程由程序执行(也就是在用户态执行)
- 协程比线程更加轻量
- 多核处理器的情况下,多个线程是可以并行的,但是运行的协程的函数却只有一个,其他协程都会被suspend(阻塞)。即协程是并发的,但不是并行的。
- 执行密集型IO操作,性能提高
- 在协程之间的切换不需要涉及任何系统调用或任何阻塞调用
IO
多路复用IO
执行A事件,同时执行B事件,通过状态下发,获取A,B执行状态
信号驱动IO
异步IO
执行A事件,通过异步处理,当A事件处理完成不哦,通知主进程/线程
阻塞IO:
执行完A事件,在执行B事件
非阻塞IO
执行A事件,同时执行B事件,一直监听A,B的执行过程
Kotlin
kotlin协程?
kotlin协程使用Coroutine,通过使用函数挂起(非阻塞挂起)的方式来保证协程的使用,内部使用状态机来管理协程的挂起点
每当遇到suspend修饰的方法,都有可能会挂起当前的协程,通过GlobalScope.launch或者其他方式执行suspend修饰的方法时,进行挂起操作
suspend,runBlocking,launch,withContext,async,doAsync之间的区别
suspend:挂起函数的标志
runBlocking:阻塞式全局协程
launch:非阻塞全局协程
withContext:任务是串行的
async:任务是并行的
doAsync:封装java的Future类,便于线程切换的,并非协程
网络篇
HTTP和HTTPS
简述一次完整的Http请求过程
通过域名请求后————>DNS域名解析为ip地址————>中间路由跳转————>直接访问ip地址进行三次握手————>tcp三次握手成功后进行通信响应———>tcp四次挥手结束通信
客户端:
- 在浏览器输入网址。
- 浏览器解析网址,并生成http请求消息。
- 浏览器调用系统解析器,发送消息到DNS服务器查询域名对应的ip。
- 拿到ip后,和请求消息一起交给操作系统协议栈的TCP模块。
- 将数据分成一个个数据包,并加上TCP报头形成TCP数据包。
- TCP报头包括发送方端口号、接收方端口号、数据包的序号、ACK号。
- 然后将TCP消息交给IP模块。
- IP模块会添加IP头部和MAC头部。
- IP头部包括IP地址,为IP模块使用,MAC头部包括MAC地址,为数据链路层使用。
- IP模块会把整个消息包交给网络硬件,也就是数据链路层,比如以太网,WIFI等。
- 然后网卡会将这些包转换成电信号或者在光信号,通过网线或者光纤发送出去,再由路由器等转发设备送达接收方。
服务器端:
- 数据包到达服务器的数据链路层,比如以太网,然后会将其转换为数据包(数字信号)交给IP模块。
- IP模块会将MAC头部和IP头部后面的内容,也就是TCP数据包发送给TCP模块。
- TCP模块会解析TCP头信息,然后和客户端沟通表示收到这个数据包了。
- TCP模块在收到消息的所有数据包之后,就会封装好消息,生成相应报文发给应用层,也就是HTTP层。
- HTTP层收到消息,比如是HTML数据,就会解析这个HTML数据,最终绘制到浏览器页面上。
简述三次握手和四次挥手
三次握手:
客户端发送一个随机seq=100
服务端返回一个随机seq=200,ack=100+1
客户端返回一个ack=200+1
四次挥手:
客户端发送一个FIN=1,seq=100
服务端发送一个ack=100+1
服务端发送一个FIN=1,seq=200
客户端发送一个ack=200+1
服务端发送两次的原因是需要等待服务器处理当前任务完毕。
为什么需要三次握手而不是2次或者4次?
防止已失效的连接请求又传送到服务器端,因而产生错误
两次的话,服务端是不知道自己的请求是否成功发送到客户端的。但是服务端又会认为连接建立成功了。假设第二次丢失了,客户端认为服务端没有响应,就会重发一次,这样已经失效的连接请求就会传送到服务端。
tcp是可靠的双方通信协议,所以双方都会生成一个初始的序列号供双方确认,如果改成两次,只会确定客户端对于服务端具有可靠性,而服务端对客户端没有可靠性
四次的话,太过繁琐
为什么握手需要三次?挥手却需要四次?
因为挥手的时候需要等待服务器将本次连接中的所有保文都处理完,在发送关闭状态,说白了,服务器需要等待自身进入可关闭状态
握手可以携带数据信息吗?
第三次请求可以携带数据信息,客户端认为连接已经建立的,就可以携带参数,但是前两次不能,容易造成对服务器的攻击
为什么TIME_WAIT状态需要等待2MSL才能转换到CLOSE状态?
- 保证最后一次能成功到达服务器。最后一次客户端发送给服务端的确认信息可能丢失,如果丢失,服务端会有重试机制,等待一来一回的时间,也就是2MSL的时间,如果没有接收到服务端的重试请求,就认为服务端接收了,等到了就刷新2MSL时间
- 等待2MSL的时间也是为了防止失效连接的请求报文会出现在新连接中,防止第三次重试请求能被客户端接受,不会干扰其他请求
SSL层在传输层还是应用层?
SSL层在传输层和应用层之间,是一个SSL层
滑动窗口?
拥塞控制?
TCP和UDP的区别?
1、基于连接与无连接;
2、对系统资源的要求(TCP较多,UDP少);
3、UDP程序结构较简单;
4、流模式与数据报模式 ;
5、TCP保证数据正确性,UDP可能丢包;
6、TCP保证数据顺序,UDP不保证。
常见状态码
1XX - 临时消息。服务器收到请求,需要请求者继续操作。
2XX - 请求成功。请求成功收到,理解并处理。
3XX - 重定向。需要进一步的操作以完成请求。
4XX - 客户端错误。请求包含语法错误或无法完成请求。
5XX - 服务器错误。服务器在处理请求的过程中发生了错误。
200:客户端请求成功
301:资源(网页等)被永久转移到其他URL
302:重定向,临时跳转
400:客户端请求存在语法错误,不能给被服务器理解(Bad Request)
404:请求资源不存在,错误的URL
500:服务器内部发生了不可预料的错误
502:网关错误(Bad Getway)
503:服务器当前不能处理客户端的请求,一段时间后可能恢复正常。(Server Unavailable)
简述TCP和UDP的区别
TCP:需要数据准确、顺序不能错、要求稳定可靠的场景就需要用到TCP。
UDP:数据即时性
socket
tcp内部是由socket协议填充的
简述https的加密过程
RSA是非对称加密,AES是对称加密
- 客户端请求服务端进行访问
- 服务端创建RSA,获得私钥和公钥
- 服务端发送公钥给客户端
- 客户端经过复杂的证书验证
- 客户端生成AES密钥
- 将AES密钥经过RSA公钥加密后发送给服务端
- 服务端通过RSA私钥解密获取AES密钥
- 客户端和服务端后续通过AES密钥进行通信
为什么要使用RSA加密形式交换AES密钥,不直接使用RSA加密?
因为RSA加密有性能上的损耗,加解密过程会比较耗时,不适用于频繁通信过程,而AES加密比较快捷
简述中间人攻击,如何解决?(dns劫持)
- 客户端访问域名A,向服务端进行请求
- 中间人劫持dns,使之指向私人ip B。即客户端同B建立https连接
- B在和A建立https连接
- 服务端创建RSA,获得公钥(S)和私钥(S)
- 服务端发送公钥(S)给客户端
- 中间人拦截信息,获得公钥(S)
- 生成RSA公钥(中)和私钥(中),并将公钥(中)发送给客户端
- 客户端生成AES密钥
- 使用公钥(中)加密AES密钥,并发送给服务端
- 中间人拦截信息,获得加密信息,使用私钥(中)进行解密,获得AES密钥
- 中间人使用公钥(S)加密AES密钥,并发送给服务端
- 服务端通过私钥(S)进行解密,获得AES密钥。
到此为止,中间人持有客户端和服务端交换的AES密钥,可以进行消息拦截,并解密信息
解决方案:将RSA公钥交给CA机构,CA机构添加上域名,有效期等将其制作成证书,在用CA机构的私钥进行加密后放置在服务器上,当客户端请求时,返回加密后信息,客户端从CA机构获取公钥(一般情况下内置在机器中)进行解密,成功解密后,获取的信息,域名等可以匹配上,则CA验证通过,获得服务器公钥,走下面流程。
https 无法防止中间人攻击,只有做证书固定ssl-pinning 或者 apk中预置证书做自签名验证可以防中间人攻击
证书固定(Certificate Pinning)是指Client端内置Server端真正的公钥证书。在HTTPS请求时,Server端发给客户端的公钥证书必须与Client端内置的公钥证书一致,请求才会成功。
http分层



dns污染
国家或地区防止摸一个网站被访问,是dns发送出错误的ip地址,使之无法访问
使用代理服务器和vpn
http1.0、http1.1和http2.0的区别
1.0:短暂连接,重复访问,连接无法复用
1.1:支持持久连接,长连接,优化1.0带来的性能问题,可以多路复用(数量限制),串行处理,一条失败,后续全部失败,同步
2.0:优化多路复用机制,header压缩,并行处理,异步
3.0:UDP
算法篇
| 排序方法 | 时间复杂度(平均) | 时间复杂度(最坏) | 时间复杂度(最好) | 空间复杂度 | 稳定性 | 复杂性 |
|---|---|---|---|---|---|---|
| 直接插入排序 | O(n2)O(n2) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 稳定 | 简单 |
| 希尔排序 | O(nlog2n)O(nlog2n) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 不稳定 | 较复杂 |
| 直接选择排序 | O(n2)O(n2) | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 不稳定 | 简单 |
| 堆排序 | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(1)O(1) | 不稳定 | 较复杂 |
| 冒泡排序 | O(n2)O(n2) | O(n2)O(n2) | O(n)O(n) | O(1)O(1) | 稳定 | 简单 |
| 快速排序 | O(nlog2n)O(nlog2n) | O(n2)O(n2) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | 不稳定 | 较复杂 |
| 归并排序 | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(nlog2n)O(nlog2n) | O(n)O(n) | 稳定 | 较复杂 |
| 基数排序 | O(d(n+r))O(d(n+r)) | O(d(n+r))O(d(n+r)) | O(d(n+r))O(d(n+r)) | O(n+r)O(n+r) | 稳定 | 较复杂 |
冒泡排序(BubbleSort)
依次比较两个相邻的元素,如果顺序错误就交换,直到跑完所有元素,那么最后一个元素就是最大(最小)的值,在接着按照上述操作进行排序。
时间复杂度:O(n^2)
1 | private void bubbleSort(int a[]){ |
选择排序
第一趟找出最小的放在第一个,第二趟找出第二小的放在第二个,。。。。。
时间复杂度:O(n^2)
1 | public static void selectSort(int a[]){ |
快速排序(QuickSort)
分治法:将一大块分解成若干小块,一块一块算
- 设置一边的值为哨兵
- 将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
- 在对剩下的区间进行排序
1 | private void quickSort(int a[],int left,int right){ |
二分插入:
1 | while (lo <= hi) { |
插入排序
从尾部开始遍历,每次–,比他大的值后移一位,直到找到相等或者比它小的,直接赋值
1 |
扑克牌算法
根节点到目标节点的路径
找出最小的k个数
- 使用快速排序:O(nlogn)
1 | public static int[] getLeastNumbers1(int[] input, int k) { |
- 新建一个数组,放入数组前k个数,并由小到大排列好,遍历原数组,如果存在比新数组中的值更小,插入排序,而后得到新数组。
- 小根堆实现,按顺序放入小根堆—大顶堆(父节点<=子节点),小根堆大小为k,超过大小,删除堆顶元素,相反的话,加入大根堆—小顶堆(父节点>=子节点)
二分查找法
1 | /** |
一个整形数组里求两个数的和能不能等于一个给定数
- 如果数组是有序的,两个下标,如果相加大于给定数,左边–,如果小于给定数,右边++,直到数据相等或者右边等于左边
1 | int[] a = {1,4,5,7,9,12,56,456}; |
- 如果数组是无序的
1 | public static void twoSum(int[] nums,int target){ |
连续子数组的最大和
1 | public int maxSubArray(int[] nums) { |
摩尔投票法
1 | class Solution { |
二叉树
二叉树遍历
1 | //层序遍历 |
两个view第一个公共父view
- 引入set集和,一个用来存贮a数据,将b放入a数组,当数组重复会返回false,放入另一个set中做返回。
1 | public static Set<Integer> getIds(Integer[] a, Integer[] b){ |
如果想知道两个数组的索引,使用map存储,key是值,value是数组索引,在进行map.containsKey()对比,找到则使用
- 将a数组放入set中,将b轮询放入set中,返回false,则重复值
1 | public static void getIds(int a[], int b[]) { |
- 两个链表中第一个根节点
两个指针分别跑两条链,短的跑完后,将长的头赋值过去,再开始跑,长的跑完亦然,最终两指针相交地方为两链表的第一个根节点
1 | public static void getNode(Node nodeA, Node nodeB) { |
- 二叉树的最近公共祖先
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30class Solution {
TreeNode node;
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
dps(root,p,q);
return node;
}
public boolean dps(TreeNode root, TreeNode p, TreeNode q){
if(root == null){
return false;
}
if(root.val == p.val){
node = p;
return true;
}
if(root.val == q.val){
node = q;
return true;
}
boolean a = dps(root.left,p,q);
boolean b = dps(root.right,p,q);
if(a && b){
node = root;
}
if(a || b){
return true;
}
return false;
}
}
判断链表是不是环链,并返回入口
两个指针,一个一次跑一个,一个一次跑两个,相交的话就是存在环链
将跑的慢的从头开始一个一个跑,跑的快的从相交的点开始跑,一个一个跑,最终相遇的就是入口
1 | public static Node isCircle(Node node) { |
有一个整型数组,包含正数和负数,将负数放在左边,且保证相对位置保持不变
转化成链表,遍历链表将复苏和单独成链后连接到剩下的正数链上
数组两个索引,一个索引记录负数的尾部,一个所以负责遍历,每找到一个负数,将其插入该值,后续值后移一位。
1 | public static void get(int a[]){ |
打印蛇形矩阵
1 | class Solution { |
求二叉树的叶子节点数
1 | public int testTree(Tree tree){ |
求二叉树的深度
1 | public static int treeDepth(TreeNode root) { |
动态规划
数组最大和
累加值:一个一个累加的值
最大值:记录累加值的最大值
假设数组为最大,每次添加一个值,如果i-1的值<0,那么把i放入累加值,如果>0,那么将i的值加到累加值,如果累加值>最大值,则更新最大值。
如果需要数组的最大和的下标,对最大值的下标进行记录
1 | public static void main(String[] args) { |
有面值为1,3,5的硬币若干,需要凑成11元需要多少硬币,凑成n元最少需要多少硬币?
模式篇
单例
饿汉:线程安全,类初始化的时候就会触发类的实例化,所以保证只有一个,
缺点:但是会浪费内存,如果不使用单例,就会一直存在
1 | public class Singleton { |
懒汉:synchronized加锁线程安全
1 | public class Singleton { |
双重校验锁:双重加锁(线程安全)
1 | public class Singleton { |
- 双重判断的原因?
- 第一个判断减少锁的使用,提升性能
- 多个线程同时等待锁,当第一个创建后,就不需要其他线程重复重建
- volatile的理解
- 禁止重排序导致instance获取失败(3)。
- new Singleton()方法执行时可能导致分配了空间,并指向了内存空间,但是没有赋值,这样另一个线程拿到后会导致出错
静态内部类:(线程安全)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Singleton {
//私有构造方法
private Singleton (){
}
private static class SingletonHelper{
//声明成员变量
private static final Singleton instance = new Singleton();
}
//对外提供接口获取该实例
public static Singleton getSingleton(){
return SingletonHelper.instance;
}
}
枚举单例:(线程安全)
1 | public enum Singleton { |
生产者消费者
生产者添加数据,消费者自己从中间件中获取信息,通过中间件管理数据
1 | import java.util.ArrayList; |
观察者
发布者发送数据到订阅者
1 | import java.util.ArrayList; |
建造者模式
提供复杂参数的对象构造,完全由调用方选择参数配置,反之使用默认。
1 | public class Computer { |
工厂模式
代理模式
对原有功能进行封装,访问对象不能直接访问原有功能,只能访问我们的功能传达,我们就是代理,作为原有功能和访问对象之间的中介
静态代理:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42package proxy;
public class ProxyTest {
public static void main(String[] args) {
Proxy proxy = new Proxy();
proxy.Request();
}
}
//抽象主题
interface Subject {
void Request();
}
//真实主题
class RealSubject implements Subject {
public void Request() {
System.out.println("访问真实主题方法...");
}
}
//代理
class Proxy implements Subject {
private RealSubject realSubject;
public void Request() {
if (realSubject == null) {
realSubject = new RealSubject();
}
preRequest();
realSubject.Request();
postRequest();
}
public void preRequest() {
System.out.println("访问真实主题之前的预处理。");
}
public void postRequest() {
System.out.println("访问真实主题之后的后续处理。");
}
}
动态代理:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25IRetrofit iRetrofit = (IRetrofit) Proxy.newProxyInstance(IRetrofit.class.getClassLoader(), new Class<?>[]{IRetrofit.class}, new InvocationHandler() {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("-----调用前执行");
if(method.getDeclaringClass() == Object.class) {
System.out.println("-----调用前执行Object");
return method.invoke(IRetrofit.class, args);
}
IRetrofit iRetrofit1 = new IRetrofit() {
public void test() {
System.out.println("------test1");
}
public void kang() {
System.out.println("------kang1");
}
};
Object object = method.invoke(iRetrofit1,args);
System.out.println("-------调用后执行");
return null;
}
});
iRetrofit.kang();
打印如下:1
2
3-----调用前执行
------kang1
-------调用后执行
即想调用那个方法都可以,在invoke中做了代理,利用反射执行该类
设计六种原则
单一职责
接口业务单一
里氏替换原则
依赖倒置
接口隔离
迪米特法则
开闭原则
提高复用性,可拓展性,将业务抽取单一获取
根据业务功能进行划分,功能复杂时考虑分层思想+设计模式,如果业务简单,可以直接套用设计模式进行方案优化,最后业务决定框架选型,细节方面可以面向未来考虑 尽量保证良好的扩展和健壮性
Flutter
widget树,skia 2d渲染引擎,
StatelessWidget:不能更新状态的布局,创建一次,永不可修改外观
StatefulWidget:可以更新界面,通过setState方法更新布局,外观
fish-redux
Kotlin
优势
完全兼容Java
更少的空指针异常
更少的代码量,更快的开发速度
React Native
redux
action:用户触发程序
reducer:根据action,做不同响应,返回一个新state
store:存储state的集合,数据是不可变的
亮点
iot触发日志文件上传
通过bugly埋点,如果无法解决或者问题不全,或者酒店反馈音箱有问题
存储:监听时间广播,整点会重新存储日志文件,进程设置adb命令存储文件
每次中断或者时间到了都会触发重新开辟文件存储和老文件删除(只存储72个文件,正常情况下对应72个小时的)
内存优化
使用leakcanary检测内存泄漏,绑定生命周期,在onDestroy的时候创建弱引用,放置在弱引用队列中,手动gc,如果查到该Activity,就是造成了内存泄漏,会打印出dump栈堆信息
selinux权限配置
ota中遇到的问题,ota升级失败后,再日志中分析问题,再对应的.te文件中添加权限配置,循环往复,最终关闭这个权限校验。
定义每个用户,进程,应用,文件的访问和转变的权限,使用安全策略组控制这些实体
启动优化
如何检测?
AOP(AspectJ)打点
程序打点
TraceView
1
2
3
4//开始收集
Debug.startMethodTracing("app_trace");
//结束收集
Debug.stopMethodTracing();生成app_trace.trace文件,可以查看方法耗时
函数插桩(ASM)
具体的优化方案
- 替换主题中theme,保证不会出现闪屏
- decroView.post执行延时任务
- IdleHandler闲置时间进行任务执行
- 异步线程池处理
- 基于dex文件的异步加载,在编译期间对dex按模块进行拆分,把一级页面及配置放置在第一个dex中,二三级页面及配置放置在第二个dex中。
- 在app启动过程中,不启动odex转化进程,在app启动后,自己启动一个odex进程,将转化后文件放入odex文件
在app启动过程中,android虚拟机会启动一个odex转化进程,将dex转化为odex,避免这个odex进程对前台app的影响很重要
主旨核心
- 减法为主:尽量不影响主线程,能较少的启动就减少启动
- 异步为辅:耗时任务在异步调用
- 延迟为补:延迟加载增加全面性
优化方案
在使用Aspect进行时间的监测时,发现Application和Activity中的初始化三方进程耗费了大量时间,在初始化时,我们开启了百度OTA服务,Bugly监测服务,咪咕音乐服务,阿里IOT服务,日志监测服务,Linphone语音服务,Ifly语音服务等,这些串行起来是比较耗时的。
所以我们采用开启一个线程池的方案,在子线程启动这些服务,对于OTA,IOT,日志检测,Linphone等服务不需要在第一时间初始化,所以放到线程池中根据执行顺序分别初始化。但是对于咪咕、Ifly和bugly来说,需要第一时间初始化,才能进行后边的逻辑,所以我们将这些服务优先初始化,并联合CountDownLatch,当必须的服务初始化完成后,才进入下面的流程。
对于必须要在主线程进行初始化的操作,可能会造成主线程繁忙卡顿,所以使用IdleHandler方法,在主线程空闲时执行,
具体优化了40%,由2.3s压缩到1.4s。
如果由任务A,B,C,D,要求C在A之后执行,D在B之后执行,那么直接将A,C合并为一个任务,放入线程池中运行,B、D合并为一个任务,放入线池程中执行,如需决定AC和BD的顺序,那么可以按照AC、BD的顺序依次放入子线程中。
通过异步线程池进行异步加载处理,使用有向无环图算法控制任务进入线程池的顺序,通过CountDownLatch控制线程的执行顺序,进行异步加载
如何对IDLEHandler进行顺序划分?比如先执行B,在执行A
规划一个空闲队列,在Handler空闲时进行处理,每次出队优先级最高的,其他等到下次空闲在执行
2-5是怎么计算的?
1 | Math.max(2, Math.min(CPU_COUNT - 1, 5)) |
CPU_COUNT - 1,是因为为了避免后台任务将 CPU 资源完全耗尽, 减掉的这个1 是留给我们 主线程 使用的。
cpu密集型的线程选择:n+1
io密集型的线程选择:
- 2n+1
- 线程数 = CPU核心数/(1-阻塞系数),一般情况下IO密集型的为0.8,0.9,可适当调整这个数值
在改启动器中,我们存在的大都是cpu密集型任务,理论上选择n+1,但是目前在2-5中间进行选择
在最新版本的AsyncTask中的线程池已经设置为了5
如何看待app startUp?
官方提供的启动优化方案,可以规定初始化模块的运行顺序,配合AndroidManifest+ContentProvider进行初始化。
在Application的生命周期中,application.attachBaseContext()—->contentProvider.onCreate()—–>application.onCreate()
通过创建一个ContentProvider,在ContentProvider中执行初始化事件,减轻application的负担。
缺点:
- 只支持同步事件,没有线程池做异步处理
- 需要编写大量的xxInitializer类文件,配置AndroidManifest文
设计一个模块:
- 接口的易用性,从易用出发
- 命名规范
- 尽量不依赖第三方库,避免重复引用
- 多端使用的一致性,比如都开放同一个端口
- sdk包保证小而精
- 保证老旧版本的兼容性
- 这类配置项一般就不需要提供 get 方法,防止接口太多
组件化构件
布局优化
view的布局
ConstraintLayout,FrameLayout,RelativeLayout和LinearLayout的区别
ConstraintLayout:约束布局,完美结合RelativeLayout和LinearLayout的属性,可以拖拽,可以放置在相对布局,也可以按比例设置view,很像flex,都是一层布局
FrameLayout:后一个布局会覆盖前一个布局,可以控制层级
RelativeLayout:相对位置的布局
LinearLayout:线性布局,水平,垂直,比例分配
include,viewstub,merge的区别
include:复用布局
viewstub:可以显示网络布局,默认显示一次,更加省cpu和内存,只会构建一次,
merge:去除不必要的节点嵌套(比如多个LinearLayout的嵌套)
尽量使用ConstraintLayout,RelativeLayout,使用include,viewstub加载网络异常界面显示,merge去掉不必要的节点
布局优化
- 针对复杂布局使用ConstraintLayout,减少层级,实现类Flex布局,后期也可拓展为MotionLayout,添加动画
- 针对简单布局,使用LinearLayout布局,不增加嵌套层级情况下,性能最优,onMeasure渲染一次
- 使用include布局对公共布局进行封装,便于统一修改和查看
- 使用merge标签作为根布局进行include内布局的封装,当其他布局引用时,会直接当作include布局的根布局使用,减少嵌套布局层级
- 使用viewStub标签,第一次展示时不会进行绘制,他是一个轻量级的view,没有尺寸,当需要使用布局时(调用inflate()方法),才会进行加载
- 使用开发者选项中的过度绘制进行检查并优化布局
apk体积优化
使用apk Analyzer分析apk,体积主要在lib库,assets库,res库
从150M压缩到50M,
lib库中存放着三方库,所以需要对三方库进行整理,剔除不需要的库,针对so库,剔除其他架构的so库,只留了armeabi-v7a包。
assets库和res库中主要是一些音频文件,帧动画图片,gif图片等
- 对图片进行压缩,使用tinypng进行图片压缩(支持png和jpg格式)
- 大部分图片可以使用webp格式替换,减少体积
- 帧动画和gif尽量换成lottie动画
- 使用lint删除无用资源和代码
- 大图换小图
- 代码优化整理复用
- view整理复用
- 启动shrinkResources,移除不用的资源
- 大库换小库,能不用就不用
- 减小assets,raw的文件目录大小,尽量放置在网络上
- 调整需求,减少体量